This repository contains the various MayaData Culture Guides/Handbooks and is the central repository of guidance for how we run the company. As part of our value of being transparent, our handbook published in this repository is open to the world. We welcome feedback. Please make a merge request to suggest improvements or add clarifications. If your question is not covered here, please use issues to ask questions.
MayaData -- The Purpose
MayaData evolves around these few things:
- We build open source container attached storage.
- Container attached storage is per workload cloud-native storage that unlocks the productivity of these small teams; we sometimes think of it as DevOps friendly storage.
- Cloud-native is an approach to building and operating software that has certain basic principles that are closely related to DevOps.
It is incumbent upon everyone that works at MayaData to understand the above. That sounds simple -- it is only three things after all -- but when you dig into the definition of Container Attached Storage and thereby start searching for definitions of cloud-native and DevOps you can easily find yourself understanding concepts at a high level but missing the essence of them if you have not spent a lot of time with SRE and infrastructure teams to actually see how they operate.
Only our curiosity and empathy can save us here. We must try to really understand what it is like to be our target persona -- Kubernetes SREs whether workload Kubernetes SREs or platform Kubernetes SREs; as an aside I believe we do much better for the former than for the latter which makes a certain amount of sense since workload Kubernetes SREs are closer to developers and the latter, platform SREs, are typically much more senior in the organization and focus on outcomes and operations and overall operational architecture as opposed to writing and running components. Product management and a (soon to be) great process or even a driven set of founders cannot substitute for our own empathy and understanding of the experience of our users. I’ve tried to emphasize this repeatedly, at one point making the perhaps hyperbolic statement that “we are all in product management”. The context for that statement was the above train of thought; without empathy for our users, we are doomed, or at least we are never going to be better than average and that would be a shame.
MayaData Vision & Guiding Principles
Our north star remains Data Agility -- this is our vision and as such, it is aspirational which means that by design it is not something that appears in an immediate backlog. Data Agility refers to a future in which small teams innovate in building data-centric applications free from all sorts of nasty technical and organizational dependencies that historically have slowed them down. These include:
-
Shared everything storage -- your requirements conflict w/ my requirements and we share a massive blast radius beyond our control
-
Cloud lock in -- teams that rely on being spoon-fed by a particular cloud eventually end up being beaten by teams that are more able to select best of breed components from the clouds or from on-premise systems
-
Central DB as a service that cannot be fully configured for a particular use; data mesh is a pattern that is supplanting the one DB to rule them all of the past
-
Monolithic architectures that require the software to be released at best quarterly as opposed to minute by minute in a high performing organization
Here are a few practical implications for the design of our software and services that we may not have fully embraced in the past:
-
Automation is fundamental: human interaction to tweak the settings means treating the containers as pets, not cattle. That is an anti-pattern not consistent w/ cloud-native and Container Attached Storage.
-
Design for failure: Kubernetes and the cloud-native pattern assumes that everything will fail at some point. Chaos engineering such as the Litmus Chaos project we started and developed into a viable project enforces the need to design for failure by creating failures in systems.
-
GitOps: Building off the importance of automation - the desired state of the environment is in the repository, i.e. GitOps is fundamental.
-
Loosely Coupled may be the two most important words in the CNCF’s definition of cloud native. The need for loose coupling is one reason why our users like Steven Bower do not want to use shared storage. One video we have in the welcome and onboarding slides is this interview with Steven.
-
APIs and Declarative approach: Loosely coupled and the existence of many sub-components suggests there are clear APIs including within the product and typically declarative approaches are used
-
Cloud operations including auto-scaling: Cloud-native also tends to imply cloud scalability - the ability to scale UP and scale DOWN.
We will know we are succeeding in enabling our personas when a standard user of Kubernetes can grab OpenEBS and:
-
grok it -- what it is supposed to do, how it is designed, how it is explained
-
and operate it -- knowing that it will behave in a cloud-native or container attached storage way
…while the Kubernetes SREs within the Platform Team can support the use of OpenEBS at scale because they will be able to do their job. We have more work to do here in defining what these platform teams require -- thankfully we are in frequent contact with them at places such as Bloomberg, Flipkart and Optoro.
Last but certainly not least -- we are working with data and increasingly important data that needs to be secured at least for some period of time. We must avoid losing data, understanding that solutions such as flavors of OpenEBS LocalPV themselves by design do nothing to secure the data. Remember the old saying, when our users lose their data they typically lose their jobs.
As a final thought, our technology strategy can be described as giving freedom to the developers and the workload SREs while selling control and operability at scale to the enterprise and platform SREs. We believe in open source as a far better way to get more customers to pay us than traditional, expensive, much much slower to scale direct sales only approaches. That said if and when appropriate, aspects of our software to be used by large enterprises in particular, as well as future SaaS editions, would not necessarily be open source. We resolve such questions by looking at our north star -- Data Agility -- and our core values first and then secondarily by what would be good for immediate revenues and other considerations.
What is Culture
Culture is a framework that is used for day-to-day interactions and decision making. When in conflict, the culture established and accepted is used to resolve differences.
Why are we writing this document?
Culture can be a secret ingredient that increases user adoption, product quality, employee engagement and well being. By writing down our shared assumptions and aspirations about our culture, we hope to improve and sustain our culture as our company grows and transforms to better address user needs.
History shows that employees either leave or really invest their best selves into organizations depending on the culture. Our values help us to prevent the five dysfunctions.
- Absence of trust (unwilling to be vulnerable within the group) => prevented by people first, specifically kindness
- Fear of conflict (seeking artificial harmony over constructive passionate debate) => prevented by openness, specifically directness
- Lack of commitment (feigning buy-in for group decisions creates ambiguity throughout the organization) => prevented by openness, specifically directness
- Avoidance of accountability (ducking the responsibility to call peers on counterproductive behavior which sets low standards) => prevented by winning, and openness
- Inattention to results (focusing on personal success, status and ego before team success) => prevented by people first and winning
Our Mission
We want MayaData to be the preferred place to work for engineers, computer scientists, community advocates and others that believe in our company mission to limit cloud lock-in while providing higher levels of control of the data layer to DevOps teams. We recognize that in order to achieve our mission we have to be the best team possible at building and running the right software based solutions to our customer’s problems. We commit to always working to improve MayaData - and ourselves - to delight our customers. Our culture plays a key role in achieving this mission.
Specifically:
- When we talk about the best team possible we emphasize that we expect high degrees of collaboration and teamwork; if you cannot work with a team with multiple cultures with high degrees of sensitivity then we are likely not the right place for you. We seek to be the preferred employer for the best contributors in Bangalore and other markets in which we hire.
- When we talk about building software we emphasize that we focus on the productivity of our engineering teams and will be relentless in improving their ability to respond to customers quickly. We will aggressively seek to continuously improve our CI/CD and operations abilities for example.
- When we talk about running software we emphasize a DevOps approach so that if you write the code, you support the customers and you lead efforts to fix any bugs.
- When we talk about the right software we emphasize listening to users. We believe everyone at MayaData can learn from users and customers and that the best learning comes from users actually using software as opposed to simply talking about it. In order to learn from internal users, we believe in dog fooding which is the practice by which we will always use our own software if it is at all applicable to our use cases. Development environments, staging, and CI/CD and of course operations should all be based on OpenEBS and OpenEBS Director.
Our Values
We stand by our PLOW values. They empower each of us to determine what to do without asking our manager.
Additional Resources
This site expands the MayaData secret plan for world domination and converts the plan into a culture we aspire to achieve as well as concrete actions to implement and measure adoption of the culture.
We have also covered topic of the Container Attached Storage multiple times including:
- Back in 2018: Container Attached Storage: a Primer
- Updated in the Fall of 2020: Container Attached Storage is Cloud Native Storage (CAS)
And others such as the New Stack in a series sponsored by the CNCF have also written about the concept of Container Attached Storage.
Credits and Inspiration
GitLab Handbook is a true source of inspiration for anyone praticing the Open Culture. We have developed our handbook by our own experiences, as well as those mentioned in the GitLab handbook which directly reflect our PLOW culture. Another great source of inspiration and a must read are The Open Organization book series by Jim Whitehurst. On similar note, are the Amazon’s Leadership Principles.
Excellent inspiration for building great organizations are also An Everyone Culture: Becoming a Deliberately Developmental Organization by Lisa Laskow Lahey, Robert Kegan and Principles: Life and Work by Ray Dalio.
Many of us read the book Accelerate -- and we discussed it as a company a couple of times. It remains one of those books that we would welcome anyone on the team buying and expensing. Others along these lines are the Phoenix project and The DevOps Handbook.
Contributor Covenant Code of Conduct
Our Pledge
In the interest of fostering an open and welcoming environment, we as contributors and maintainers pledge to making participation in our project and our community a harassment-free experience for everyone, regardless of age, body size, disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socio-economic status, nationality, personal appearance, race, religion, or sexual identity and orientation.
Our Standards
Examples of behavior that contributes to creating a positive environment include:
- Using welcoming and inclusive language
- Being respectful of differing viewpoints and experiences
- Gracefully accepting constructive criticism
- Focusing on what is best for the community
- Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
- The use of sexualized language or imagery and unwelcome sexual attention or advances
- Trolling, insulting/derogatory comments, and personal or political attacks
- Public or private harassment
- Publishing others' private information, such as a physical or electronic address, without explicit permission
- Other conduct which could reasonably be considered inappropriate in a professional setting
Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable behavior and are expected to take appropriate and fair corrective action in response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, or to ban temporarily or permanently any contributor for other behaviors that they deem inappropriate, threatening, offensive, or harmful.
Scope
This Code of Conduct applies both within project spaces and in public spaces when an individual is representing the project or its community. Examples of representing a project or community include using an official project e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event. Representation of a project may be further defined and clarified by project maintainers.
Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be reported by contacting the project team at support@mayadata.io. All complaints will be reviewed and investigated and will result in a response that is deemed necessary and appropriate to the circumstances. The project team is obligated to maintain confidentiality with regard to the reporter of an incident. Further details of specific enforcement policies may be posted separately.
Project maintainers who do not follow or enforce the Code of Conduct in good faith may face temporary or permanent repercussions as determined by other members of the project's leadership.
Attribution
This Code of Conduct is adapted from the Contributor Covenant, version 1.4, available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
For answers to common questions about this code of conduct, see https://www.contributor-covenant.org/faq
PLOW
MayaData’s values are People First, Listen to Learn, Openness, Ownership and Winning together spelled as PLOW. Our values are interlinked and work together to protect our culture. This document gives some examples that make our PLOW actionable.
- People first. People before deadlines. People before sales figures. When in doubt, we seek to do what is best for each other and for our users and community members.
- Listen to learn. We seek to out-listen our competition. We understand that anyone can understand most of a problem by researching it and thinking about it - but to delight customers requires really understanding their stated and unstated needs.
- Openness. In all things we seek to be open. We use ChatOps and other systems to “over communicate” internally. And to the extent possible, we share with the community our issues, plans, and even our concerns.
- Ownership. We want each team member to be a manager of one who doesn't need daily check-ins to achieve their goals.
- Winning. We win. We are confident in our abilities as a team to dramatically improve the experience of our users. We know that a proper focus and unrelenting effort will eventually get us recognized as one of the world’s most useful companies by our users for their use cases. We know winners never quit, never blink, never back down from any challenge. And winners laugh a lot too.
Note the helpful acronym PLOW.
Tactics
Here are some tactics we use to insure we are living up to our values:
- Open source: we believe that open source is a force for good in the world that is completely consistent with our beliefs in openness and listening. We support open source projects whether they directly help our products or not. This means engineering allocates time to be useful contributors to these communities, including crafting useful issues and contributing code when possible. Similarly, we volunteer time with Linux,Gopher,CNCF and other communities and support them via marketing funds and by providing free access to our open source Cafe whenever possible. We will all be evaluated in part based on contributions to our own and related communities.
- Getting to know users and each other: We seek to understand users and each others as individuals. This means we take the time to know a little bit about them - where did they go to school, what do they do when they are not working, do they like Go or C better, and so forth. We document our understanding of users.
- Listening and openness: We look for and reward team members that go out of their way to clarify and communicate their actions. Everything from comments in code to useful commit comments as well as of course communications via Chat and in person with other team members will be considered. We must keep in mind that we are a global company and need to think about how to include non local teammates in discussions and decisions.
- Winning: We celebrate new users and new customers, new releases and other achievements. We respect our competitors however we don't worry about what they are doing. And we are tenacious, and we share our commitment with each other and with the community and users; for example, if a user has a problem we tell them "this will get fixed. Quickly. Please open your PR and we will turn around a response for you."
About our Values
We take inspiration from other companies, and we always go for solutions that are easy to implement. Just like the rest of our work, we continually adjust our values and strive always to make them better. Everyone is welcome to suggest improvements.
People First
All business - and arguably life itself - comes down to people. Whether working with our team, or the community, or customers, or partners or others - we strive to remember and to reinforce our common humanity.
Helping others is a priority, even when it is not immediately related to the goals that you are trying to achieve. Similarly, you can rely on others for help and advice - in fact; you're expected to do so. Anyone can chime in on any subject, just like in good families. As companies grow their speed of decision making goes down since there are more people involved. When you are the person who’s responsible for the work, you decide how to do it, but you should always take the suggestions seriously and try to respond and explain why it may or may not have been implemented.
Make someone’s day today
It is a long journey. Over time happy team members are healthier, productive and bring positivity to others. Remember, we all want to be in a group where we are happy. Be thoughtful and kind just because you can. Catch people doing things right. Help a team member who's having a difficult time or need mentors. Be a good listener. Share your joy.
Kindness
We value caring for others. Give as much positive feedback as you can and do it in a public way.
Say thanks
Recognize the people that helped you publicly, for example in our #say-thanks chat channel or via LinkedIn Give Kudos.
Negative is 1-1
Give negative feedback in the smallest setting possible, one-on-one video calls are preferred. Remember, we are all on the same boat. And the purpose of negative feedback is not to hurt a person, it is go get MayaData better and better and win together and to help that person learn and progress.
Speakup
If you are unhappy with anything (your duties, your colleague, your boss, your salary, your location, your computer, the sloppiness of a colleague, or anything else) please let your boss, or the CEO, know as soon as you realize it. We want to solve problems while they are small.
Get to know each other
We use a lot of Slack communication and if you know the person behind the text it will be easier to prevent conflicts. Please help encourage people to get to know each other on a personal level through our team calls, virtual coffee breaks, events and during company gatherings.
Give feedback effectively
Giving feedback is challenging, but it's important to deliver it effectively. When providing feedback, always make it about the work itself; focus on the business impact and not the person. Make sure to provide at least one clear and recent example. If a person is going through a hard time in their personal life, then take that into account. An example of giving positive feedback is our #say-thanks chat channel. For managers, it's important to realize that employees react to a negative incident with their managers six times more strongly than they do to a positive one. Keeping that in mind, if an error is so inconsequential that the value gained from providing criticism is low, it might make sense to keep that feedback to yourself. In the situations where negative feedback must be given, focus on the purpose for that feedback: to improve the employee’s performance going forward. Give recognition generously, in the open, and often to generate more engagement from your team.
Don't pull rank
If you have to remind someone of the position you have in the company you're doing something wrong, people already know we have a hierarchical decision making process. Explain why you're making the decision and respect everyone irrespective of their function.
Don’t label other teams
An anti pattern that counters being people first is being “group first”. Beware the rise of capitalized words to identify groups of unclearly defined “others”. For example, avoid phrases like “Support just does not understand our code” or “Engineering does not care about us.” Similarly, remember there is one team (and yes one system…) and that this MayaData team is comprised of all of us plus the community of users, customers and partners. So avoid prioritizing the needs of ones own immediate coworkers over what is best for the user, company, community and other stakeholders. When in doubt prioritize the needs of the user and especially customers above all else.
Assume positive intent
We naturally have a double standard when it comes to the actions of others. We blame circumstances for our own mistakes, but individuals for theirs. This double standard is called the Fundamental Attribution Error. In order to mitigate this bias you should always assume positive intent in your interactions with others, respecting their expertise and giving them grace in the face of what you might perceive as mistakes.
Address behavior, but don't label people
There is a lot of good in this article about not wanting jerks on our team, but we believe that jerk is a label for behavior rather than an inherent classification of a person. We avoid classifications.
Say sorry
If you made a mistake, apologize. Saying sorry is not a sign of weakness but one of strength. The people that do the most work will likely make the most mistakes. Additionally, when we share our mistakes and bring attention to them, others can learn from us, and the same mistake is less likely to be repeated by someone else.
No ego
Don't defend a point to win an argument or double-down on a mistake. You are not your work; you don't have to defend your point. You do have to search for the right answer with help from others.
People are not their work
Always make suggestions about examples of work, not the person. Say, "you didn't respond to my feedback about the design" instead of "you never listen". And, when receiving feedback, keep in mind that feedback is the best way to improve and that others want to see you succeed.
Blameless problem solving
Investigate mistakes in a way that focuses on the situational aspects of a failure’s mechanism and the decision-making process that led to the failure rather than cast blame on a person or team. We hold blameless root cause analyses and retrospectives for stakeholders to speak up without fear of punishment or retribution.
Dogfooding
We use our own product. Our SaaS service uses data management and tools that we deliver to our customers. We upgrade to the latest version before publishing it for general consumption.
Diversity and inclusion are fundamental to the success of MayaData.
We aim to make a significant impact in our efforts to foster an environment where everyone can thrive. We actively chose to build and institutionalize a culture that is inclusive and supports all employees equally in the process of achieving their professional goals. We hire globally and encourage hiring in a diverse set of countries. We work to make everyone feel welcome and to increase the participation of underrepresented minorities and nationalities in our community and company.
Do not make jokes or unfriendly remarks about race, ethnic origin, skin color, gender, or sexual orientation. Everyone has the right to feel safe when working for MayaData. We do not tolerate abuse, harassment, exclusion, discrimination or retaliation by/of any community members, including our employees. You can always refuse to deal with people who treat you badly and get out of situations that make you feel uncomfortable.
Shift working hours for a cause
Caregiving, outreach programs, and community service do not conveniently wait for regular business hours to conclude. If there's a cause or community effort taking place, feel welcome to work with your manager and shift your working hours to be available during a period where you'll have the greatest impact for good. For colleagues supporting others during these causes, document everything and strive to post recordings so it's easy for them to catch up.
Be a mentor
People feel more included when they're supported.
Family and friends first, work second
Long lasting relationships are the rocks of life and come before work.
Celebrate accomplishments with offsite events
While being frugal about spending, we also make opportunities for celebrating our accomplishments and bonding with other team members over offsite events. Our ambition is to have an all-company annual offsite meeting in the coming years. Until that happens, we will make sure the people in closer geographic circles will have quarterly events. For instance, an offsite lunch in the first and third quarters, an offsite weekend outing in the second quarter, and half-day fun activities in the fourth quarter.
Listen to learn
Listen to users
Listen to users in the openebs-users, sig-storage, kubernetes / litmus channels and various other social channels online and offline, ask clarifying questions and even just ask them whether your understanding is correct by using phrases like “can you confirm that I got it right? You are experiencing X and would like to understand Y?”. Learn and document the use cases that users are trying to solve.
Listen to peers
Listen to peers and their fears about the solution. The fears may be founded on the research and experience they bring. Validate possible solutions by talking to users.
It's impossible to know everything
We know we must rely on others for the expertise they have that we don't. It's ok to admit you don't know something and to ask for help, even if doing so makes you feel vulnerable. It is never too late to ask a question, and by doing so you can get the information you need to produce results and to strengthen your own skills as well as Mayadata as a whole. After your question is answered, please document the answer so that it can be shared. Don't display surprise when people say they don't know something, as it is important that everyone feels comfortable saying "I don't know" and "I don't understand." (As inspired by Recurse.)
Remove rigid barriers around your domain.
People joining the company frequently are hesitant to provide feedback. At MayaData we should be more accepting of people taking initiative in trying to improve things. You must make them feel comfortable and allow others contribute to your domain. Actively seek feedback. Again, do not label people or teams and don’t forget your primary allegiances should be to customer success and to the company.
Boring solutions
Use the simplest and most boring solution for a problem, and remember that “boring” should not be conflated with “bad” or “technical debt.” The speed of innovation for our organization and product is constrained by the total complexity we have added so far, so every little reduction in complexity helps. Don’t pick an interesting technology just to make your work more fun; using established, popular tech will ensure a more stable and more familiar experience for you and other contributors.
Make a conscious effort to recognize the constraints of others within the team. For example, sales is hard because you are dependent on another organization, and development is hard because you have to preserve the ability to quickly improve the product in the future.
Efficiency for the right group
Optimize solutions globally for the broader MayaData community and specifically for our customers and users. Making a process efficient for one person or a small group may not be the most efficient outcome for the whole community. As an example, it may be best to choose a process making things slightly less efficient for you while making things massively more efficient for thousands of customers. In a decision, ask yourself "for whom does this need to be most efficient?". Quite often, the answer may be your users, contributors, customers, or team members that are dependent upon your decision. When in doubt, choose to understand, support, help and delight the customer user.
Openness
We build our software in the open. We collaborate with users in the open. And we strive to build a radically open culture.
Be open about as many things as possible. By making information public we can reduce the threshold to contribution and make collaboration easier.
Openness creates awareness for MayaData, allows us to reach out to people that care about our culture, it gets us more and faster feedback from people outside the company, and makes it easier to collaborate with them. It is also about sharing great software, documentation, examples, lessons, and processes with the world in the spirit of open source, which we believe creates more value than it captures.
Everyone can remind anyone in the company about our values. If there is a disagreement about the interpretations, the discussion can be escalated to more people within the company without repercussions.
Public by default
Everything at MayaData is public by default unless it’s documented otherwise here. A good practice is to move DMs in chat onto a public channel, perhaps creating a thread to limit impact on that channel. This way for example anyone can search on a subject and find your conversation, thereby reducing ramp up time and limiting costs of coordination.
Examples of not public information.
Not public by default are the following items that may impact our users and employees and doesn’t benefit being public:
- Security vulnerabilities are not public since it would allow attackers to compromise MayaData installations.
- Financial information, including revenue and costs for the company.
- Deals with external parties like contracts and approving and paying invoices.
- Content that would violate confidentiality for a MayaData team-member, customer, or user.
- Legal discussions are not public due to the purpose of Attorney-Client Privilege.
- Some information is kept confidential by the People Group to protect the privacy, safety, and security of team members and applicants.
- Partnerships with other companies are not public since the partners are frequently not comfortable with that.
- Acquisition offers for us are not public since informing people of an acquisition that might not happen can be very disruptive.
- Acquisition offers we give are not public since the organization being acquired frequently prefers to have them stay private.
- Customer information in issues.
- Competitive sales and marketing campaign planning is confidential since we want to minimize the time the competition has to respond to it.
- When we discuss a customer by name that is not public unless we're sure the customer is OK with that.
- Plans for reorganizations are not public and on a need-to-know basis within the organization. Reorganizations cause disruption and the plans tend to change a lot before being finalized, so being public about them prolongs the disruption. We will keep relevant team-members informed whenever possible.
- R&D that has not made it to the published road map or the open source POC level is not public.
- There is a huge amount that we all know about why users buy, what are the weaknesses of competitors, where Kubernetes and standards like NVMe and similar area headed that are not proprietary and yet also fit into a level of understanding that is uncommon in the broader industry and as such should be treated as valuable and discussed only when needed to help users, customers, partners and other stakeholders
Share problems
Share problems you run into, ask for help, be forthcoming with information and speak up. For example, consider making private issues public wherever possible so that we can all learn from the experience.
Measure what matters and publish it publicly
Agree in writing on measurable goals. Within the company we use public OKRs for that. You don't always get results and this will result in criticism from yourself and/or others. We believe our talents can be developed through hard work, good strategies, and input from others. We try to hire people based on their trajectory, not their pedigree.
Write things down
We document everything: in the handbook, in meeting notes, in issues. We do that because "the faintest pencil is better than the sharpest memory." It is far more efficient to read a document at your convenience than to have to ask and explain. Having something in version control also lets everyone contribute suggestions to improve it.
Bias towards asynchronous communication
Take initiative to operate asynchronously whenever possible. This shows care and consideration for those who may not be in the same time zone, are traveling outside of their usual time zone, or are structuring their day around pressing commitments at home or in their community. In other words, use chat, GitHub or other issue tracker and so forth whenever possible.
Anyone and anything can be questioned.
Any past decisions and guidelines are open to questioning as long as you act in accordance with them until they are changed.
Disagree and commit.
Everything can be questioned but as long as a decision is in place we expect people to commit to executing it, which is a common principle. Sometimes you will not fully understand a decision. Feel free to bring it up later as we may need to revisit the decision. In the meantime, keep going.
Say why, not just what
Whenever possible, take the extra time to explain changes in policies or approaches - especially when you are adding additional steps that someone must take before their work has an impact; as an example, additional test and validation changes are inevitable and also should be well explained. A change with no public explanation can lead to a lot of extra rounds of questioning and can be considered a kind of “communication debt” that must be paid off at some point. Avoid using terms such as "industry standard" or "best practices" as they are vague, opaque, and don't provide enough context as a reason for a change.
Ownership
We want each team member to be a manager of one who doesn't need daily check-ins to achieve their goals.
We expect team members to complete tasks that they pick up or are assigned. Having a task means you are responsible for anticipating and solving problems. As an owner you are responsible for overcoming challenges and there are no excuses. Take initiative and proactively inform stakeholders when there is something you might not be able to solve.
Do it yourself
No need to brainstorm, wait for consensus, or do with two what you can do yourself. If you think it is better than what is there now do it, no need to wait for something polished. A task done today is better than a polished result delayed indefinitely.
Outcome, not output
We care about what you achieve; the code you shipped, the user you made happy, and the team member you helped. Someone who took the afternoon off shouldn't feel like they did something wrong. You don't have to defend how you spend your day. We trust team members to do the right thing instead of having rigid rules. If you are working too many hours, talk to your manager to discuss solutions.
Be your own boss
You should have clear objectives and the freedom to work on them as you see fit. If a meeting doesn't seem interesting and someone's active participation is not critical to the outcome of the meeting, they can always opt to not attend, or during a video call they can work on other things if they want. Staying in the call may still make sense even if you are working on other tasks, so other peers can ping you and get fast answers when needed. This is particularly useful in multi-purpose meetings where you may be involved for just a few minutes.
Global optimization
This name comes from the quick guide to Stripe's culture. Our definition of global optimization is that you do what is best for the organization as a whole. Don't optimize for the goals of your immediate team when it negatively impacts the goals of other teams, our customer users, and/or the company. Those goals are also your problem and your job. Keep your immediate team as lean as possible, and help other teams achieve their goals.
Be respectful of others' time
Consider the time investment you are asking others to make with meetings and permission process. Try to avoid meetings, and if one is necessary, try to make attendance optional for as many people as possible. Any meeting should have an agenda linked from the invite, you should document the outcome. Instead of having people ask permission, trust their judgment and offer a consultation process if they have questions.
Spend company money like it's your own
Every dollar we spend will have to be earned back; be as frugal with company money as you are with your own. Amazon states it best: "Accomplish more with less. Constraints breed resourcefulness, self-sufficiency and invention. There are no extra points for growing headcount, budget size or fixed expense.”
Responsibility over rigidity
When possible we give people the responsibility to make a decision and hold them accountable for that instead of imposing rules and approval processes.
Accept mistakes
Not every problem should lead to a new process to prevent them. Additional processes make all actions more inefficient, a mistake only affects one.
An algorithm for distributed decision making
Use narratives, check sheets, and other tools. If you are proposing a new approach, sometimes a meeting isn’t enough and neither is a chat discussion. If you believe MayaData teams or the broader community or others need to align in a certain way to achieve an outcome, please take the time to articulate your reasoning in narrative form. This approach borrows heavily on the narrative structure used by Amazon.
Another technique we embrace is the use of criteria based trade off matrices; this approach starts with outlining the problem and 2-3 alternatives, then turns to listing the criteria by which these alternatives can be judged, and then turns to creating weights for each of these criteria.
The use of Narratives and Trade Off Matricies are important aspects of our internal operating system. Workshops and onboarding training sessions help to distribute these important algorithms.
Winning
Working at MayaData will expose you to situations of various levels of difficulty and complexity. This requires focus, and the ability to defer gratification. We value the ability to maintain focus and motivation when work is tough and asking for help when needed.
We prefer making results count over perfecting the process. We assume nothing and we keep pushing ourselves until the job is done. We keep our promises and make sure our people keep their promises.
Confidence
A winner knows deep down that she or he deserves to win and that confidence itself - no matter what the situation - is crucial to achieve a positive outcome. There is rarely success without commitment and rarely commitment without confidence.
See others succeed
We win as a single team and we take pride in contributing towards make each other succeed. If anyone is blocked by you, on a question, your approval, or a merge request review, your top priority is always to unblock them, either directly or through helping them find someone else who can, even if this takes time away from your own or your immediate team's priorities.
Sense of urgency
At an exponentially scaling startup time gained or lost has compounding effects. Try to get the results as fast as possible so the compounding of results can begin and we can focus on the next improvement.
Ambitious and always polishing yourself
While we iterate with small changes, we strive for large, ambitious results. You keep picking yourself up, dusting yourself off, and quickly get going again having learned a little more.
Bias for Action
It's important that we keep our focus on action, and don't fall into the trap of analysis paralysis or sticking to a slow, quiet path without risk. Decisions should be thoughtful, but delivering fast results requires the fearless acceptance of occasionally making mistakes; our bias for action also allows us to course correct quickly.
Accepting Uncertainty
The ability to accept that there are things that we don’t know about the work we’re trying to do, and that the best way to drive out that uncertainty is not by layering analysis and conjecture over it, but rather accepting it and moving forward, driving it out as we go along. Wrong solutions can be fixed, but non-existent ones aren’t adjustable at all. The Clever PM Blog.
Move fast by shipping the minimum viable change
We value constant improvement by iterating quickly, month after month. If a task is too big to deliver in one month, cut the scope.
Reduce Cycle time
We do the smallest thing possible and get it out as quickly as possible. This value is the one people most misunderstood when they join MayaData. People are trained that if you don't deliver a perfect or polished thing you get dinged for it. If you do just one piece of something you have to come back to it. Doing the whole thing seems more efficient, even though it isn't. If the complete picture is not clear your work might not be perceived as you want it to be perceived. It seems better to make a comprehensive product. They see other people in the MayaData organization being really effective with iteration but don't know how to make the transition, and it's hard to shake the fear that constant iteration can lead to shipping lower-quality work or a worse product.
However, if we take smaller steps and ship smaller simpler features, we get feedback sooner. Instead of spending time working on the wrong feature or going in the wrong direction, we can ship the smallest product, receive fast feedback, and course correct.
The way to resolve this is to write down only what you can do with the time you have for this project right now. That might be 5 minutes or 2 hours. Think of what you can complete in that time that would improve the current situation. Don't write a large plan, only write the first step. Trust that you'll know better how to proceed after something is released. You're doing it right if you're slightly embarrassed by the minimal feature set shipped in the first iteration.
People might ask why something was not perfect. In that case, mention that it was an iteration, you spent only "x" amount of time on it, and that the next iteration will contain "y" and be ready on "z".
Focus on Improvement
We believe great companies sound negative because they focus on what they can improve, not on what is working. Our first question in every conversation with someone outside the company should be: what do you think we can improve? This doesn't mean we don't recognize our successes, for example see our Say Thanks value. We are positive about the future of the company; we are present day pessimists and long term optimists.
When we iterate slowly
In some cases, rapid iteration can get in the way of results. For example when adjusting our marketing messaging (where consistency is key), product categories (where we've set development plans), sales methodologies (where we've trained our teams) and this values page (where we use the values to guide all MayaData team-members). In those instances we add additional review to the approval process, not to prohibit, but to be more deliberate in our iteration. The change process is documented on the page and takes place via merge request approvals.
Reproducibility
Enable everybody involved to come to the same conclusion as you. This not only involves reasoning, but also, for example providing raw data and not just plots; scripts to automate tasks and not just the work they have done; and documenting steps while analyzing a problem. Do your best to make the line of thinking transparent to others even if they may disagree. Increases accountability when making decisions and difficult choices.
Life is full of learning opportunities
Every job has work that’s less fun than other parts. Every team has projects that succeed, and projects that fail. One of the key determinants of winning individuals is to embrace what you can learn from failure and what you can learn from the parts of the job that you don’t like. Is there a rote task that needs doing and no one wants to do? Figure out how to automate it, how to make it more efficient, or how to do without it at all. Is something wrong with your project and everything is on fire? What can you learn? It’s only a mistake if you do it twice; otherwise it’s just something that you learned from.
Basic security awareness
MayaData is a storage company, we help companies to store their data. Our users expect us to keep security as one of the key design principles. We also have access or store data about our customers, partners and contributors. No matter what kind of data it is, it's always the best to pretend that all the data are sensitive and one should treat them with special care, because we care about all the people's data. The way how one should care about the data has also been well formed in past years into set of rules hidden under well-known shortcut GDPR.
Basic set of principles to follow to stay on secure side
To stay on the safe side and minimize the surface to any kind of attacks or data leakage, you may find useful the following set of rules (it's split to simple categories for better memorization).
Environment
- Always treat the environment you work in as insecure. We work in so called All remote setup and the working environment cannot be protected centrally. It's each one of us responsibility to behave responsibly and treat all your steps with special care.
- Follow the least privilege principle. From time to time you'll find out that you weren't given full access to the technology you work with. It's not about the fact that you're not a trusted person, but it's about leaving the opportunity window less open to the attacker, who may get in possession of your credentials (no matter how (s)he did that).
- Do not leave your unlocked computer unattended. Same applies for your apartment right? You're not leaving doors open, so why would you leave the computer? Most of the time there's a magic key combination
Win+Lto lock your computer (the key combination may vary depending on your setup). - Shout out loud in case of any stolen device or you feel you were the victim of cyber attack that is related with your work for MayaData! The sooner the better!
- for security related reports there's security [at] mayadata.io
Hardware
- Omit the usage of devices made by unverified manufacturers aka cheap Chinese whatever tend to be full of pre-installed malware, that can start sending company data to 3rd parties. Same applies for example for USB sticks you found or were given.
- Always encrypt your data in your HW. Especially the hard drives in your work computer. For multi-OS installations, it's better to encrypt each OS with it's own key, but you may use HW encryption provided by the manufacturer.
- Treat all your devices the same. Even your iPhone or your Alexa are prone to multiple different kind of attacks, it's always best to use such devices as little as possible for work purposes (the best is never), or use the same security principles as you use for your work computer.
- Always wipe your data once you pass your device to someone else. You're passing your device the service-man, returning borrowed or selling the device - always wipe the data that are present in your device. Should you need to restore the data, make a proper backup.
Network
- Do not connect to insecure WiFi networks. Unless you really really have to. By using the open WiFi network you're removing one additional layer of security on the way to your data and making it easier to sniff your connections to others in closest surroundings.
- Do not let untrusted (sometimes called smart) devices to connect your WiFi networks. So called IoT devices floods the world with rapid speed. The price for the rapid spread is the absence of proper implementation of security measures. Hacked IoT devices can become a gateway to your network only a single step to your data in your computer.
Software
- Always encrypt wherever you can encrypt all the connections you make against the outside world. Do not trust unprotected paths, because there always can be somebody else listening and waiting for your data.
- Do not pass the data through the insecure channels without additional layer of data encryption. This applies especially for the email communication, where one may tend to send the results of his computation as an email attachment.
- Prefer 2FA authentication wherever possible and make it harder to steal your credentials.
- Use different password for each site. One rule them all applies even for passwords. By using different password for each you're giving an access to only a single site instead of all of them in case some will steal your credentials. With a password manager like bitwarden or for offline lovers pass you don't have to remember any of them and they also solve problem of generating strong passwords and storing them securely.
- Use strong passwords doesn't mean you need to put every weird character into it:
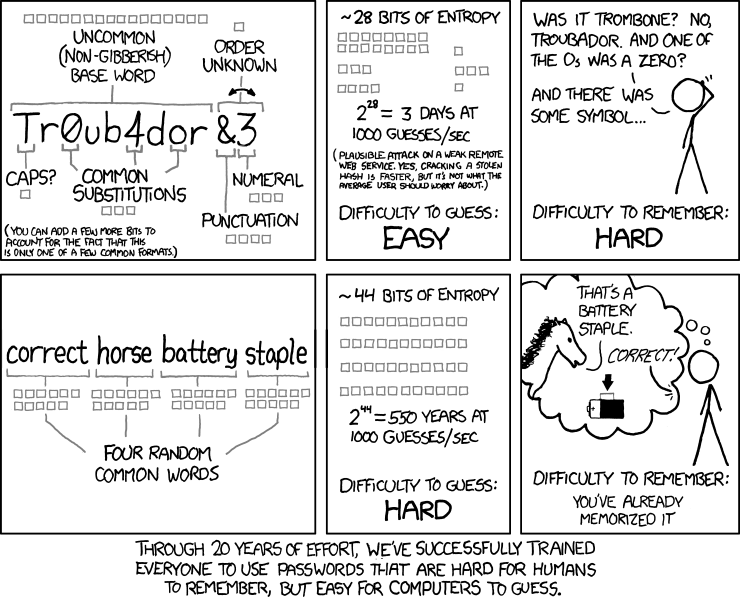
- Never share passwords and never let them lay around in plain text.
- Use strong ciphers for your keys or certificates. Applies for all different types of keys, but mostly we're talking about SSH keys and communication / encryption certificates. You may not be secured even with 2048bit RSA on these days.
- Always use the latest updates for the software installed on your computer, especially the security updates are important to be present.
- Do not expose (let listen) services without further firewall limitations on your work computer. Even though you think you're safe on local network and you can expose your docker daemon, because you don't have public IP, don't do that without additional firewall.
- BACKUP! Encrypt the backup data and verify that it's possible to restore the data, periodically.
- Do not download / run unverified apps.
- Beware of browser extensions. Web browser became one of the most used applications today and may contain a lot of personal data. Extensions improves the browser functions, but even the least expected extension can be harmful and send your data elsewhere without further notice.
- Use multiple different browsers. One for private work and one for your job work. Or at least different profile folder for each part of your work. This is more or less for your own security, but people tend to visit broad range of different sites within their free time (games sites etc.) that they won't visit withing the work time. These sites tend be compromised and may try to steal the data from your browser. Splitting it into multiple profiles, you're limiting the attack surface.
- Beware of phishing / s(p|c)am etc. Even though you're an expert, it's better to be cautious. You may read more at Gitlab's handbook about some examples.
- Beware of clicking the links in the emails / on the web pages. It's not that hard to put a different path under the visible text. Hover over it and see the bottom left side, your email client / browser will show you the real path you'll be take to.
How to 2FA
2FA (or two factor authentication, or two step verification) refers to use of an additional secret in conjunction with your password. There are multiple ways how to implement 2nd factor. These can be hardware tokens (such as Yubikey), time based one-time-passwords (TOTP, Google Authenticator, Authy, also a lot of password managers have support for it) or even your phone (e.g. Google Prompts).
Adding your additional factor is typically trivial, we put together list of the most frequently used services:
- Google account or just go to Your Google Account;
- GitHub account;
- Amazon Web Services (AWS);
Many services will also allow multiple different factors to be configured. For example, this is list of my other factors configured for Google Account: 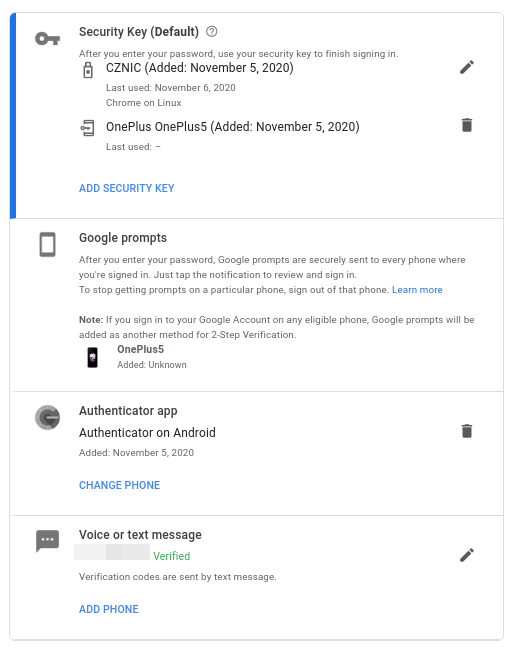
In case service or you don't have or don't want to have multiple different 2nd factor configured, services typically allow generating backup codes that can be used (one time each) instead of / as the 2nd factor. In that case it is recommended to generate those and store them securely (password manager) in case you lose access to your 2FA device.
Summary
The basic rule of thumb is to be CAUTIOUS, always and anytime! Even though it may sound stupid, if you spot something suspicious, like the fact that your WiFi authentication disappeared suddenly, it may mean that someone else replaced it with his own evil twin version to sniff your credentials.
Don't be afraid to ask, if you are unsure. It's better to ask stupid question then be sorry for not asking it.
These are just a bunch of basic rules that everyone should follow. For more inspiration, take a look at Gitlab's handbook security section or search the internet for other sources (for example advanced reading compiled by NIST).
Household manners
This section covers some suggestions that are considered good household manners.
Cultural sensitivities
We are spread across geographies and different cultures.
- We will use open channels for communication as much as possible to keep the conversations transparent.
- In case there are direct discussions between two individuals, the relevant content will be diligently documented and posted on Slack for everyone's benefit.
- Each of us will remain sensitive to make comments about an individual’s ignorance in the meetings and slack channels. No questions are stupid.
- Similarly, some cultures are more direct and candid than others. We strive to be as candid as possible - while remembering people first. Giving direct feedback is more kind than hiding one's opinion not just for that person but for all the other team members. We are all depending on each other learning fast and no one is perfect.
Online meetings (voice or video)
- On-time, there is always a ramp-up time due to unforeseen reboots which we all have which is fine
- Be prepared, find a calm place, with as little background noise as possible
- Don’t eat during the call the crispy sounds can be heard better than you think!
- Mute yourself, there’s a mute button for a reason. It might not seem like it, but there’s a lot of background noise even in the quietest of offices. There may also be feedback you can’t hear, but everyone else can. Unless you’re speaking, keep your phone on mute. However, don’t use this feature as an excuse to sneak a snack. Refer back to the last point for a reminder.
- Make sure to say goodbye, and do so with a smile
- When group calling, don't use a cell phone on speaker, they are not sufficient
- If you must use for whatever reason (did you prepare?) make sure that it does not vibrate
- In video calls, keep the camera on when possible. This is important for the mental health of people working from their homes.
In-person meetings / Online meetings
- Plan to attend on time, others are waiting for you
- Meetings are scheduled to discuss openly with an expected outcome of clearing doubts if there are any. Ask your doubts in the meeting. A meeting is not successful if you had a doubt before the meeting, and it continues to exist after meeting because you did not bring it up
- Avoid one-on-one chats in the meeting.
- Feel free to share information. Make it short, precise and relevant to the meeting agenda. Try not to interrupt a team member when they are speaking.
Say thank you on Slack especially
- We don't spend much time together in person as a team. This introduces the risk that misunderstandings can be amplified over time. Therefore we go out of our way to thank each other for their comments even if we disagree with them or do not yet fully understand them.
- When we read something that resonates or is helpful on Slack we make an effort to take an extra second or two to give a thumbs up or to say thank you. Especially for remote workers this kind of interaction can provide useful feedback.
Jira Hygiene
As almost anything, even Jira, requires regular maintenance to address:
- Incomplete/unclear tickets
- Stale/outdated tickets
- Forgotten/unpopular tickets
- Usefulness of Jira content as a whole
Why? Even though it might not look like it at first glance, Jira is a tool to communicate with people in an open, transparent and remote-friendly manner and facilitate reaching our goals. This article tries to apply our PLOW to working with Jira. To keep various Jira projects open and welcoming. To allow us to cooperate effectively and win - personally and professionally and deliver the value that is useful to the company and open-source community in a repeatable and dependable manner.
Two Loops
For Jira to be an effective communication tool, information must flow freely while being taken care of at every stage.
The First Loop -- Initial Triage
Person responsible for maintenance should regularly -- at least daily -- check new tickets flowing into the project (status open). In case of projects that can receive time sensitive tasks (e.g. operations/SRE, customer support) it is recommended to set up a notification channel for new tickets (if you like email - see PLOW-22; there's a possibility to send new tickets to slack channel but consider that shared responsibility often doesn't work and unnecessary interrupts and notifications are especially harmful to deep complex work we do here, so it is recommended to point this integration to a special channel for this purpose. Especially avoid channels with more than few involved members).
It is required to take care of every new ticket, it does not mean that every ticket will be worked on when received. Probably incomplete list of what to do with new tasks:
-
Ticket is clear, understandable and actionable, contains why, what and any particularities required. Also has all required metadata. It is aligned with team priorities, OKRs and company's strategy. Such tickets should be accepted for prioritization. In case of urgent tickets these must skip prioritization and must be taken care of immediately with clearly agreed ownership.
-
If a ticket does not fit any or all criteria written above it must be fixed. Possibly by:
- Adding additional information if known to a particular project maintainer
- Making required decisions if applicable.
- Reaching out to the author (ticket assignment works well) to provide missing pieces or explanation, alignment of priorities - consider having shorter discussions in slack as when ticket description is fixed and/or augmented, comments might become perplexing or superfluous to further work with the ticket and make communication harder not easier. If you need longer discussion, a design document/meeting or similar tool should probably be used. It is the project maintainer's responsibility to make sure this happens.
- Closing the ticket with a good description of why you did that (duplicate tickets are an obvious example).
- Moving ticket to a different project if appropriate.
The Second Loop -- Health Check
Even if every new ticket is catered for projects always tend to accumulate a bit of dust. For that reason regular review of all project's tickets needs to be done. It is recommended doing that on a weekly basis. Ideally most of the work described here is done by the ticket owner but loop two guarantees that it happens even if for any reason the owner hasn't or couldn't.
This would mainly consist of:
- Going through all tickets one by one (from experience, after few iterations it can be done in about 30 minutes for a 500 ticket board of a sizeable team)
- Validating each ticket still makes sense and is correctly prioritized as in agile development priorities might shift wildly. In case of failure to pass this test ticket should be deprioritized or even closed with a clear comment why. Consider commenting even when deprioritizing to keep - potentially unknown - colleagues and stakeholders in the loop and able to react.
- Making sure unpopular/maintenance/forgotten tickets are taken care of eventually.
- Validating all tickets have proper status:
- Are in-progress tickets progressing? (communicating by putting ticket back from in progress to previous states is valid fix)
- Are blocked tickets still blocked?
- Are PRs being done in a timely manner?
- Is someone struggling with a ticket without a reaction?
- Validating miscellaneous conditions like are in-progress tickets assigned, all stakeholders are kept in the loop, etc.
- Ticket updates/comments are also clear and understandable. Questions are answered.
- Giving the team a good pat on the back for its work.
Responsibilities and Perks
Main responsibility to make this happen is on Lead Engineer (put your project manager's hat on), however she/he might choose to delegate or rotate responsibilities in the team. Some of the responsibilities might also be automated. Until they are, they however must be done manually. Lead Engineer should motivate the team to keep its Jira as clean as possible by default.
It is recommended that the second loop be done by Lead Engineer herself/himself before the team's regular grooming/prioritization sessions. It will have additional value of coming to grooming/prioritization meetings prepared with refreshed knowledge of tasks at hand as Lead Engineer often has to explain work at hand in terms of why and how it connects to other tasks in near term, other projects and motivate team members to do the work by conveying its purpose and meaning in a broader context. Moreover regular maintenance of workboard brings intuitive understanding of team's current priorities and short/mid-term plans which, from experience, is quite useful for leadership role and helps with many responsibilities Lead Engineer has as reporting progress outside the team (if at all needed with clean project), answering and aligning team members about priorities, avoiding work duplication and in general keeping the team "well oiled" and working at its best performance. And it feels really good.
Meetings
Meeting can be the most effective way how reach agreement. But too many meetings can kill the company.
General Rules for Meetings
- Feel free to schedule a meeting according to attendees' calendar. We generally try to keep them up to date.
- Always be on time for the meeting (especially if you are the organizer). If you are late, let attendees know.
- Keep number of attendees to the absolute minimum. Always remember, that 8 people on the 1h meeting is equal to the whole working day!
- Always specify reasons for the meeting, provide an initial agenda. Allot time and owner to the respective topics, if you have a broader audience.
- Provide a link to a living meeting minutes document, especially for broader calls. Exceptions would be for 1:1’s / other meetings that are individual in nature.
- Always consider recording the meeting.
Narrative memos instead of Slideware
This applies to internal meetings.
Slides are important for external communication, many people just expect them. But they are also very dangerous, especially for the internal communication. As it is trivial to unintentionally hide complexity and why's. On the other hand, putting additional text on the slides is not the solution. The most impactful presentations are mostly visual.
What we are after is a though-through narrative text which provides answers to many of "why" questions which can be asked about the topic. Writing a (short) memo is harder than "writing" a 20 page powerpoint presentation because the narrative structure forces better thought and better understanding of the topic. Also it gives space to cover relationships among topics. Slide-based presentation with bullet-point lists somehow gives permission to gloss over topics, making all of them sort of same importance and most importantly leaves large space for misinterpretations.
Cross time-zones and All Company Meetings
Please attempt not to reschedule meetings with a very broad invite list, including all company meetings, less than 24 hours ahead of time. This way we can avoid our fellow teammates waking up for example before 5am in order to attend a meeting only to find out that it was rescheduled.
As in all things there will be exceptions.
Remote First
MayaData is a remote first company with team members working in different time zones and located in half-dozen countries or more. MayaData’s remote-first culture allows you to choose when and where you live and work, your work can revolve around your life as opposed to the other way around. Remote first fits perfectly with our PLOW culture of people first and openness.
Working remotely and running a remote team may seem like an outrageous idea to many, who have worked in organizations that allow their employees to occasionally work from home in case of emergencies. In our experience of running a company without a traditional head-quarters we have learnt to be more open and effective, combined with working with Open Source and Kubernetes community, the boundaries of a physical location made no sense. Thankfully we have also had a lot to learn from other companies that are successfully running an All-remote organizations like GitLab.
We strongly believe that remote-first and all remote organizations tend to attract people who place a high degree of value on autonomy, flexibility, empathy, and mobility.
While we are striving towards moving to an All-remote organization, with more than 30% of the employees already operating in all-remote, we are also committed to retain few physical offices in locations with a large concentration of Employees. We realize that such a model brings about advantages and challenges in terms of ensuring that the employees working in the office operate in a remote friendly way.
Remote-first means working remote is the default. It means making sure your remote employees are as much a part of the team as those in the office.
Remote-first means when somebody wants to present something, they’re not going to stand up at a whiteboard and write while the remotes squint at their screens trying to see it. We present electronically. It means when somebody refers to a document, they send a link to the whole group. These seem like small things. But they’re not. When you treat the coworker two desks down the same, for the most part, as you do your coworker in London, everyone has a great feeling of belonging and engagement. That leads to greater happiness and productivity for everyone.
Remote First Manifesto
- Flexible working hours over set working hours.
- Writing down and recording knowledge over verbal explanations.
- Written down processes over on-the-job training.
- Public sharing of information over need-to-know access.
- Opening up every document for editing by anyone over top-down control of documents.
- Asynchronous communication over synchronous communication.
- The results of work over the hours put in.
- Formal communication channels over informal communication channels.
Remote Employee Evaluation
-
People First. Trust that everyone is working in alignment with PLOW values and are thinking globally rather than themselves or their teams. This means that:
- Employees need to trust that their managers are looking out for their best interest.
- Managers need to trust that their employees are engaged and motivated at work. Part of this trust is built during the hiring process—selecting candidates who are self-motivated—and the rest is built over time with each positive interaction. Just like in-person office cultures, remote office cultures can differ wildly.
-
The Team Wins Together. We all win together. Success in this company is not a zero sum game. Did someone else deliver a big victory in your team? Excellent. Celebrate it, congratulate them, and learn from what they did so you can drive yourself to your next big win.
Don't tear down or minimize the victories of other people in this company. Positivity adds momentum; negativity adds drag.
-
Continuous Checkin and Feedback. If employees are more familiar working in an office environment where they receive feedback daily, the silence in a remote position can be the perfect breeding ground for Imposter Syndrome. It's easy to assume the worst about your work when you don't hear otherwise.
Regardless of whether you check-in with employees daily through a chat app, schedule weekly video sessions, or meet in-person monthly, the key is to provide continuous feedback rather than combining it all into one surprising review at the end of the year. Hold performance-oriented discussions in private, not in public. We share praise in public, and keep negative feedback to 1:1.
On weekly team meetings, you should decide, together with the team as much as possible, what is the best use of your time toward accomplishing objectives. You can expect and schedule a 1-on-1 once every month with your manager to further refine your objectives and to request support with any challenge you might face.
-
Measure Output. The underlying message is to find a metric outside of hours spent to evaluate productivity. We use a combination of OKRs and Performance Reviews to evaluate. OKRs are used to clearly articulate the priority of the tasks and enforce alignment towards Company objectives. Performance Reviews start with Self-evaluations, seeking feedback through peers and managers on the qualitative and quantitative aspects of the work as expected to the Job Roles and Responsibilities.
Every quarter we commit to do a 1-on-1 to review our performance and use the same structure to help each of us set career and personal goals. We commit to helping each other achieve these as much as it is within our power to do so.
Work is part of life, not the other way around. We do pledge Flexibility and Individual Commitment to accomplish the work that you've agreed to publicly accomplish, and the OKRs that you've agreed to be responsible for.
If you can't hit a goal this week, tell your team leaders . We don't demand 110% commitment all the time because 1) it's impossible and 2) that's how we burn out.
If you fail at them, we can have a look at why, and refine either your approach, or revise the team agreement into something more reasonable. If you fail to uphold your commitments a second time, that’s a red flag and it’s worth a more serious discussion; however, it will be in the spirit of helping you fit in the team and processes better.
If you fail often and repeatedly, you will be asked to leave the team. As such, we do not ask someone to leave lightly. Firing someone is something we view as the worst possible outcome in a work relationship. However, keeping someone that is underperforming, or doesn’t fit the team, is damaging to the work of everyone else in the company. This is a case where we must place the many above the few.
Extra Remote Office Allowance
Every employee or contractor is eligible for yearly allowance of 750USD for purchasing office equipment. This allowance is solely focused on helping making your home-work environment better, e.g. getting better chair, table, highlighting etc.
Tools and Tips
- GitLab Tools and Tips
- Zapier guide to remote productivity
- Zapier remote apps suggests
- Zapier on remote teams communication
- Remote Work 2021
Daily Standups
Having a daily stand up is an important part of knowledge sharing. That includes, but it is not limited to:
- what others are doing (to sync or avoid duplication, give opportunity to cooperate);
- express dependencies (e.g. I am waiting for some other event to happen before I can continue with my work);
- highlighting (semi-)important events, new projects, merge request (doesn't replace email for important notifications, but helps with spreading the information);
- highlighting interesting information sources (for example mentioning that interesting meeting happened and where are meeting minutes, mentioning an interesting article or task);
- status update about future plans (are we on track with our long-term goals, is some change in direction coming).
But physical standups (round tables) are frequently non-effective and actually quite hard to follow and don't give opportunity to dig deeper into topics which interests you. Also having a physical standup effectively prevents anybody from a different time-zone to participate.
How it works?
To address these issues, we have introduced a written standup. It works as follows:
- Bot creates an empty document every midnight UTC. File will be created under standups folder on Google Drive. It follows naming schema of
{year}/{month}/{year}-{month}-{day}_standup. Documents are made as copies of a template. So in case, you want to update how standups are going to look like in the future, just edit this document. - Bot publishes the link to Slack channel
#engineering-standups. Slack channel makes it really easy to go back couple standups in case you need it. - Everybody has her/his section in the document.
- Your record in the document should be finalized by the end of your work day. In other words -- you are supposed to be capturing what you have done the same day or what are you planning to be doing next day. It doesn't typically talk about yesterday (in contrast to typical standup).
- On the other hand, when you start working in the morning. Quickly go through the stand up from the previous day. That will help you to see what others have done.
- Always provide context to allow people to understand the update (links to Jira tasks, Github projects, merge requests or just link what ever you are talking about). Please format links nicely, they are read more often than written.
- If somebody asked a question / requested more details via comment, always consider updating your record in the document (in contrast to just replying to the comment). Any consecutive reader will benefit from updated text.
Please, be reasonable in picking topics to write about. You don't need to cover every single email you have read. Similarly, it would be interesting to make a research around various cuisine across the whole company, but this is not really the place to share what you had for lunch. Basically, always keep on mind, that somebody is going to read it, so pick what is valuable for potential readers.
Key Benefits of Written Standups
- One can read way faster then listen/speak. So you can cover way more people when reading their notes.
- Having a links to additional resources give opportunity to dig a bit deeper and ask meaningful questions.
- Google Document allows for inline comments which became a great tool for asking additional information asynchronously.
- It is fair for everybody, despite their schedules or time-zones. It turned to be really valuable for us, as we have teams around the globe (Asia, Africa, Europe, Americas). Standup basically follows the sun.
- Allows people who are for any reason missing on a particular standup to catch up easily.
- Produces body of searchable and rich documents.
- It also helps you to see what you have achieved during the day. And get the sense of accomplishment, which is otherwise challenging to get at knowledge jobs.
- You can use the document as a log-book. Filling it during the day. It removes burden of remembering what you have done at the end of the day. As well as it allows for faster pickup by others.
How To Google Shared Drives
We have enabled Shared Drives (by upgrading our subscription level at Google Apps). Shared Drive is a cloud incarnation of an office samba shared drive (take the parallel with a grain of salt). Note: Shared Drives used to be called Team Drives, they are the same thing.
TL;DR -- Use them! ;-)
What should you do right now
- Create a Shared Drive for your team/project;
- Move previously randomly shared documents there;
- (optional) Take the opportunity to clean up the structure a bit;
Main benefits of Shared Drives
- Team-based file ownership -- is a bigger thing that might seem. Any files stored in a Shared Drive belongs to the team. No individual member can personally claim ownership of any Shared Drive file. In case someone leaves the organization, you do not have to worry about the files stored on this drive, they will stay where they are.
- Simple discoverability of the content. When shared on standard Drive, you must either share with particular people or send them a link if shared with a group. Otherwise, they will not see shared content in their drive. This is super simple with Shared Drive as those will show up automatically at the appropriate section:
- Simple Team Management -- sharing, especially internally, is way less cumbersome. You just add people to the particular Shared Drive if they need special treatment. Or leverage groups for automation!
Please, make sure that you have added all-company group at least as a Contributor to allow access to the shared drive (obviously doesn't apply to "secret" drives, like HR, customers data etc.): 
How To use Google Calendar
Google Calendar is an essential tool for planning time, thus for allowing people to schedule calls and meet each other. But also to allow for keeping your work-life balance in check.
This chapter consists of the following sections:
- Allow access to your calendar
- Allow guest to modify invites
- Shared calendars
- Speedy meetings
- Working hours
- World clock
Allow access to your calendar
Go to Settings and click on your calendar:
Make sure, that you have allowed other in the company to see your events:
Allow guest to modify invites
Please make sure, that you have set Default guest permission under Settings -> General -> Event settings to Modify event (or at least to Invite others). This setting will allow your guests to add other people to meetings, add dial-in details, extend description etc.

Shared calendars
MayaData shared calendars
MayaData uses shared Google calendars. You can subscribe your Google calendar account to shared calendars by clicking on the following links:
- Meet Mayadata public calendar -- public calendar, that anyone can join, dedicated for sharing events relevant to MayaData.
- Mayadata Team Meetings -- for events like all hands calls, continuous improvement initiatives & demo days for internal meetings of MayaData employees.
Holidays in different countries
On the similar note, you can easily add calendars showing holidays in your home or other countries. It looks like this for me:
You can easily add other countries. Hit the + sign and then Browse calendars of interest -> Regional holidays and find the country of interest.
Speedy meetings
We suggest using Speedy meetings also under Settings -> General -> Event settings. That shortens up meetings a bit – end 30 minute meetings 5 minutes early and longer meetings 10 minutes early. That will allow people to have consecutive meetings scheduled (have you ever came late to the meeting because you need to go to the bathroom?).
Working hours
Set your working hours to give hint to the others, when they should be scheduling meetings with you. You will find it under Settings -> General -> Working Hours.
World clock
Google Calendar has built in simple world clock. I find it quite useful for making a quick decision if I am going to reach out to someone or send an email. You will find it under Settings -> General -> World clock.
Let's take a look at my settings. My configuration looks like:

That will result into

The page contains the list of Software tools, IDE etc that people at MayaData use in order to be productive at their job.
If you would like access to any of the following tools or would like to suggest purchasing or subscribing a new tool, please reach out on the MayaData Slack channel #ask.
Slack
We are using Slack for non-urgent semi real-time, simple communication. That means, that
- Nobody is required to response on Slack. Slack is treated as strictly best-effort communication platform.
- People will probably overlook messages in channels, when they get back from vacation.
- Please, don’t sent messages, which really should go via email.
- You don’t require “immediate” response.
- Person on the other side, will either need to put effort into understanding your question/comment and/or she will need to put effort into responding. Basically, if you are writing something what is longer than 3 sentences, that should probably go to email or ticket.
- Please don't send information which should be captured as Jira ticket or Confluence page only to Slack.
- We tend to use Slack as a type of “social network”. There are channels for casual conversations, sharing interesting links etc.
Please read Slack Etiquette Guide, which is an excellent overview of the key concepts for sustainable Slack.
How to Set Up Your Slack App
Elegant Puzzle by Will Larson lists ad-hoc interruptions as the second most "effective" time killer in any company:
Cit: The second most effective time thief that I've found is ad hoc interruptions: getting pinged on HipChat or Slack, taps on the shoulder, alerts from your on-call system, high-volume email lists, and so on.
The strategy here is to funnel interruptions into an increasingly small area, and then automate that area as much as possible. Ask people to file tickets, create chatbots that automate filing tickets, create a service cookbook, and so on.
But there are few ways how one can help with solving the issue in the Slack itself. On both the sending and receiving side.
Notifications, Meetings and Your Zs
It is frequently convenient to mention somebody (those @epowell). That will mark a particular message and typically trigger more aggressive notification being sent to the person. Frequently, one doesn't need to send the notification straight away. E.g. I am mentioning somebody who is already out of the office (maybe she is in a different time-zone, or maybe I am working over-time). I don't want her to respond immediately, but I want to mark the message for her...
It is your responsibility to set up working hours. You should do two things:
- check your home time zone at slack account > settings. Mine looks like this:

- open user profile. Click on "more options" (tree dots) and select View prefereces. You will be able to find Do not Disturb settings under Notifications. Mine looks like this:
-
If you want to be fancy or noticed that Slack's DnD settings do not take weekends into consideration, connect dontinterrupt.app which allows you to set DnD times schedule day by day. Moreover you can also connect your google calendar so notifications are off during your meetings and notifications from slack do not suddenly pop up to your screen while sharing it on a meeting.
-
Fine tune your notifications: I have a bunch of channels that I want to read, but do not need to be notified for each message. Right click on the channel and select Change notifications. In preferences (under workspace name Mayadata in top left corner) you can see all channels that have specific notification settings.
Source of Interruptions
One can help it on the receiving end by above settings. Sender can help a lot too. Be kind to your colleagues and create more relevant messages by setting your enter key to insert a newline instead of sending the whole message. Go to Preferences (top-left corner, click on the Mayastor workspace name and select Preferences). In Advanced you'll see:

-
Consider editing your messages instead of flooding with short "*fixed spelling" or similar messages and consider using rich text to allow readers to orient themselves quicker in longer messages.
-
Avoid directly mentioning (many) people in your message unless it's really urgent or message is really direct but you want to share it in a wider audience. Make sure the target audience is in the channel, but allow people to manage messages at their own pace. Understand that with slack one can be already in multiple discussions and starting another synchronously is humanly impossible.

-
Use threads. Seriously. It allows people to avoid notifications for discussions about topics they do not care about while reacting faster (not disabling notifications) for channels they're in. It also allows sharing conversations via thread link which is impossible if messages are spread over the channel or even interleaved with different discussions. For people in different time zones not using threads essentially prevents them from participating.
-
Replace short follow-up messages with emoji reactions.
-
Use public channels.
Slack Status
Unintrusive way for your colleagues to discover your status (whereabouts, focused work, break, sickness) rather than sending yet another notification and requiring them to remember (or search through history) is using slack status. To set slack status, click on your profile picture in the top right corner and select the Update your status option:
Your status emoji is seen with your name every time your avatar appears in slack. In conversation and on the sidebar. While hovering over the status, the status text is shown. For example you can show you're on vacation, sick, or just having a break. Set a time to clear to show when you'll be available again.


If you're lazy (the good lazy :smile:) like me dontinterrupt.app connected with your google calendar can set these slack statuses automatically and you'll help colleagues that would like to schedule a meeting with you too by keeping your calendar up to date! (pro tip: put slack emoji like :taco: in google calendar event title and dontinterrupt.app will set it to the slack for you).
There's also google calendar slack app that can set your status, but doesn't set do-not-disturb. It might still be useful not to miss last minute meetings for people who avoid notifications for every email without complex filtering rules.
Tips and Tricks
- Change channels quickly with
CTRL+K(you can set a list of ignored channels in preferences > advanced) - Create snippet with
CTRL+SHIFT+ENTER - Subscribe to existing thread by adding emoji reaction or just clicking thread menu and selecting "Follow thread".
- Use "Remind me about this" and "Add to saved items" feature to go through important non-urgent messages later.
- Ask for threads using
:thread-please:emoji. - Familiarize yourself with keyboard shortcuts (e.g.
UP/DOWNarrows,Efor edit message,Tfor thread, ... see slack shortcuts for more information)
Coding style for various languages
We have not yet defined any MayaData specific coding style. Please use style guides widely adopted in the community:
Code review
Note: Google's How to do a code review heavily influenced this document.
Code reviews are an essential part of our constant effort to improve quality of our code base. It is essential for keeping technical debt under control. Good code-review is a balancing act. We don't want to allow smelly code, but also going through review should not be a painful process, which will prevent developers from submitting features or improvements.
Key attributes which reviewers are looking for
- proposed change is consistent with the rest of the code-base;
- proposed change is maintainable (or is not making existing code harder to maintain);
- proposed change is improving the overall code health (even if the change itself is not perfect);
- proposed change is addressing product/business need described in the parent ticket.
Only exception when reviewer could approve change which is worsening overall code health is state of emergency.
Principles of code-review
-
Technical facts overrule opinions and personal preferences.
-
Style is driven by our coding style guides. We are striving to keep style consistent across the entire code-base. If something is missing from the style guide, consider proposing a change to it.
-
Code design is never purely personal decision. Sometimes there could be several options how to approach a particular problem. Author of the change should be able to demonstrate her decision process and provided reasoning for the solution chosen. Ideally, such thought process is already captured in comments or in the ticket relevant to the change. If proposed solution is equally good to reviewer's alternative, reviewer should accept author's proposal.
-
If we don't have explicit rule, reviewer can ask author to keep consistency with the rest of the code base (e.g. don't necessarily use some new language construct, if it obstructs readability of the code given the context).
-
Respond to code-review request in a timely manner. If you cannot attend code-review, let the author know and work out if you need to resign as reviewer or review can wait.
-
In cases of big code changes, always try to split change into multiple code-reviews. Is your code design correct? Could you leverage feature-flags / configuration more?
-
When appropriate, organize pair code-reviews where author meets (calls) reviewer and go through the review together. Think about pair-programming applied to reviews. How to realize, that it is time for pair-review:
- your comments became short novels, instead of couple short sentences;
- you went through your cup of tea/coffee and you are still not even reached half of the review;
- you start to question competency of the author;
- you start to think that the author was working on something totally different in parallel.
Choosing your code-reviewer
Unfortunately, automation in GitLab is currently very limited. You need to pick your reviewer manually. Phabricator is way better, but we are currently not promoting Differential flow as it is more complicated for a junior developers (also not ideal when you need to collaborate on the top of the code).
Rule of thumb for choosing your reviewer is to escape your bubble. Try to ask other people first, then your buddy sitting next you. This helps keeping engagement as well as overall understanding of the code-base. It also helps tremendously with keeping whole code-base consistent.
Also, your current reviewer can always pass the review to somebody else, if she feel appropriate. So don't worry and be curious.
Key things look for in a code-review
Reviewer should always make sure, that they have thought about the following aspects of the code. Naturally, we expect authors to think about them as well :)
- The code is well designed. (Sensible modularization of the code, appropriate paradigms being used).
- The implementation is actually addressing a need described in the implementation ticket (aka is it doing, what it should be doing?).
- The functionality is good for the user -- if used by programmers, does the API make sense? If UI change, does the change make sense to the users, does it look good?
- Any parallel programming or external services are handled safely (check for race-conditions, deadlocks, missing timeouts).
- The code isn’t more complex than it needs to be.
- The developer isn’t implementing things they might need in the future but don’t know they need now.
- Code is not weakening our security model.
- Code appropriately handles privacy of the users (for example it is not logging unnecessary personal details into application logs).
- Code has appropriate unit tests.
- Tests are well-designed.
- The developer used clear names for everything.
- Comments are clear and useful, and mostly explain why instead of what.
- Code is appropriately documented.
- The code conforms to our style guides.
Writing code-review description & commit message
When you are author getting ready to submit your fresh change for code-review. Always pay attention to the description of the code-review request. A description is a public record of what change is being made and why it was made. For writing good description apply the same principles as for writing a good commit message. Therefore we are going to cover them together. For more, read A Note About Git Commit Messages from Tim Pope and How to Write a Git Commit Message from Chris Beams.
We have agreed to follow Conventional Commits format. Please, read the specification and go through examples.
Summary of key principles of the good description or commit message:
- Separate subject from body with a blank line.
- Use the imperative mood in the subject line.
- Wrap the body at 72 characters for git commit messages.
- Use the body to explain what and why vs. how.
- Always mention related tickets (no need for full URL, just the ticket id).
Body is Informative
- Wrap the body at 72 characters for git commit messages.
The rest of the description should be informative. It might include a brief description of the problem that’s being solved, and why this is the best approach. If there are any shortcomings to the approach, they should be mentioned. If relevant, include background information such as bug numbers, benchmark results, and links to design documents.
Writing code-review comments
As mentioned at our values, always remember the human-being on the other side of the line. It is really strongly suggested to use pair-reviews for complex or problematic reviews. Always remember to
- expect competency and good intentions;
- be kind;
- comment on the code, never on the person;
- explain your reasoning, ask for explanation of author's reasoning;
- stay constructive -- suggest what should be changed;
- balance between giving explicit directions with just pointing out problems and letting the developer decide.
Also, when you needed substantial time for discussion over some topic, you should consider requesting code-rewrite (to make it more understandable) and/or extend in-code documentation. Also consider updating the implementation ticket with a summary of your findings. Code-review comments are rarely accessed retrospectively. Make a special effort to capture information, when doing pair-review.
Emergencies
Sometimes the speed of getting change out to the production outweighs having a polished code. Such change should be a small change that: allows a major launch to continue instead of rolling back, fixes a bug significantly affecting users in production, handles a pressing legal issue, closes a major security hole, etc.
In emergencies we really do care about the speed of the entire code review process, not just the speed of response. In this case only, the reviewer should care more about the speed of the review and the correctness of the code (does it actually resolve the emergency?) than anything else. Also (perhaps obviously) such reviews should take priority over all other code reviews, when they come up.
However, after the emergency is resolved you should look over the emergency code-changes again and give them a more thorough review.
Product Releases
General guidelines
- We are going to be driven mainly by the data on the quality metrics not by management push (such as, let us release today otherwise we are going to suffer a deviation from the planned milestone)
- Release Managers (Gates and gate managers) are clearly defined and the system suffers a dearly when quality is not matching as measured by an automated test system. There are going to be situations where it makes business sense to gain more market visibility that drives the releases, in such cases, the features delivered are tagged appropriately - as alpha, beta, and stable based on the metrics.
There are three products that MayaData handles currently: OpenEBS, Litmus, and OpenEBS Director.
OpenEBS releases
OpenEBS releases can be either Major (like 1.1 or 1.2) and Minor (like 1.2.1). Major releases contain features and pre-planned bug fixes. Minor releases contain emergency fixes that community users or customers are waiting for. Both these releases do not have a fixed calendar day for a release but they get released in asap model. Minor releases are delivered within a sprint. Major releases are planned into the sprints and can across multiple sprints.
OpenEBS Director releases
- The goal is to make a OpenEBS Director release everyday.
###OpenEBS Director Release process
Key stakeholders: Product Management - Ajesh Development - Vishnu Attur Product Quality - Giridhar Prasad
Release schedule:
Once in a day (Weekdays). 5PM IST Go/Nogo meeting((over the slack) : 4PM IST
Every component/module would be packaged as a helm chart versioned in the format <module>-<major_version_#>-<minor_version_#>-<release_version_#>-<commit_sha>*
Every branch runs through the various stages in our CI/CD pipeline : Stage 1: Clone the source repo for the branch to be built Stage 2: Build the code and package it as a docker image Stage 3: Run the unit test suite, gather test coverage and publish it Stage 3: Run the static analysis of vulnerabilities in application containers Stage 4: Push the docker image to docker hub Stage 5: Create a helm chart for the module and publish it. Stage 6: Deploy the helm chart and send a notification to the #production in slack. Stage 7: Run the integration test for the entire application and publish the report.
The staging branch of every module gets deployed to staging namespace. Similarly, the master branch gets deployed to production cluster(namespace)
For deployments to the production environment, we follow a release process to make sure we release the stable artifacts. Deployments to master require a PR to be raised from staging to master that results in a PR-merge branch(this happens in Jenkins and needs to be tested) that needs to go through all the 7 stages described above in a pre-prod cluster(namespace). This PR may consist of “n” number of PRs merged into the staging from their respective feature/bugfix branches and needs to be reviewed and approved by module lead, SRE(to make), QA and the management(product manager, etc.,)
Responsibilities of various teams during a production deployment include but is not limited to :
Module lead: Capture the unit test cases added for this release PRs with an appropriate description that has been merged into staging. Squash commits generally carry all relevant data. Also, make sure that the PR had been assigned a zenhub issue. Inform the SRE team on whether it was a major/minor release as mentioned up. SRE can then bump up the helm versions accordingly.
SRE Create a new release branch conforming to the nomenclature and annotated tags. Work with the developers to raise a pull request against the master and run the CI suite. Makes sure only approved features and bug fixes make it to production. Checklist has been duly followed by the module leads. Any special provisions needed for deployment? Gather the information from the module leads and draft it in DR/notes. Release notes are available for publishing to the customer. Disaster recovery plan has been drafted and the on-call group has been constituted to monitor and take any actions on MO if needed. Vote as GO/NOGO for the release to be deployed and let the team know as to why they think so.
QA Make sure that automation QA suite has run against the latest build in pre-prod Dedicate a QA team member for post deployment quick sanity checks and let the stakeholders know. Vote/Veto for the release to be deployed on the production supporting it with their arguments in favor or against it, Perform a load testing on the cluster and present the report to the team
All the discussion pertaining to the production deployment happens in the #production channel. Our goal is to automate our recordings and actions via slack being our primary chatops tool for deployment and publishing reports. Initially, we may be running a few manual steps but once such action items are identified, SRE will add them as an action item for their forthcoming sprints.
Disaster recovery and rollbacks: Ours would be an immutable infrastructure i.e., we would deploy only a blessed image to the production i.e., no changes to the server or our deployments via manual
A blessed release is one that was built when the staging branch is merged into master, runs all basic sanity checks, demonstrates a confident test coverage in CI and has been approved by all stakeholders - module lead, QA and SRE. There could be cases of dependent deployments wherein one module would be dependent on the other and also the chronological order of deployment may be of significance. We do not make the incremental changes to the infrastructure but instead, a new one would be spawned and the previous image is still available for a rollback of the environment itself to a good known state.
Note:
- Refer https://semver.org/
Developer Advocacy
Goal
To build MayaData technical brand with deep, meaningful conversations on engineering topics relevant to our industry by leveraging our community of team-members and the wider ecosystem.
- The ideal ratio of MayaData team-members to the wider community members should be 20:80. Currently we are more like 95:5. Our challenge is to solve for this while ensuring our presence in key industry events and online forums.
- Increase the adoption of MayaData products and influence the product development suited towards SRE and DevOps personas.
Why push the wider community?
Meghan Gill, former developer marketing leader at MongoDB and current VP of Sales Ops there, is a champion of leveraging the community. The reasons she gives are:
- The psychological reason: Messages about a product are always more powerful coming from a user.
- The economic reason: By investing in a community member and helping them become a great evangelist, we spend once and continually reap benefits. However, when we send team-members to conferences, we take time away from their daily jobs slowing down product development. Each time a team member leaves their desk, there is an opportunity cost which we do not have to pay with a community member.
- The sustainability reason: Once we enable community members to have a voice in the ecosystem, there is a snowball effect and they get invited to present their point of view repeatedly. Our investment is largely done but the benefit keeps coming back.
- The amplification reason: There is no way one company can reach everyone. However, with community evangelists in place, they can amplify the reach beyond a company’s corridors of influence.
Who can be a Developer Advocate?
Everybody in wider MayaData Community can be a Developer Advocate. Whether you work in marketing, ops or engineering, you have a point of view on the work you do and the ecosystem of open source enterprise technology. If you are looking for ideas to get started, reach out on #dac slack channel or look for open items under Community Interactions project(internal link).
Stages of Developer Advocacy
- Beginner - when you start following the right accounts on Twitter, peruse HN regularly, and respond to people
- Enthusiast - when you start creating content in the form of blog posts, videos, tweets, talks. Occasionally you create issues whenever you want to post something on the company blog or Medium publication.
- Pro - when you are invited to give talks that have over 200 attendees, when your content sometimes goes viral, often snagging over 500 views. You regularly contribute to the MayaData blog and other community blogs, podcasts, other content channels. At this point, you are looking at becoming a full time developer advocate. Checkout the roles of a full time developer advocate.
- Member of MayaData Influencer Board - when you are part of the MayaData partnered consortiums. You reach this stage for two reasons: you are a pro and there is a strategic benefit to MayaData to promote your thought leadership.
Current Consortiums we work with
Developer Advocates focus on Consortium marketing to bring the MayaData technical perspective to the right conversations. We define Consortiums as (often open source) groups that have come together to further a technology cause.
- Linux Foundation - Member seat
- Cloud Native Computing Foundation - Member seat
- SODA (Coming soon)
Benefits of being a Developer Advocate
- Beginners: Joining the conversation about our ecosystem is a great way to develop a more nuanced perspective of your job. That leads to new and better ideas. Being aware of the various points of view in the industry also helps jumpstart the strategic brain juices which will help you contribute more deeply in work discussions.
- Enthusiast: As an enthusiast you showcase your expertise in the public arena. This means you and your company benefit from the material and you start building name recognition that leads to new opportunities. This is also a good spot to be in if you want to pivot your career towards a new expertise.
- Pro: At this stage start being recognized as an expert. Folks want to hear from you and you get name recognition in the community. This can lead to job offers, promotions, etc.
- Members of the MayaData Influencer Board: At this point you are contributing to the MayaData strategy and story in the ecosystem. You are seen as a MayaData spokesperson and will get exposure at the largest venues. The Technical Evangelism team will help you write conference proposals and funnel opportunities to you.
Services we offer team-members and the wider MayaData community
- Find a speaker - If you want our advice and help securing a speaker proficient in a particular topic, please create an issue in the community project and tag @kmova.
- Become a speaker - Feel free to submit a PR to the community projects speakers list, if you want to be in our speaker list and are interested in being considered for any upcoming speaking opportunities.
For MayaData team-members Attending Events/ Speaking
- If you find there is an event of interest that MayaData should be represented, please reach out via the #cfp-room to check if your peers or the wider MayaData community that are Geographically closer to the event, would be interested in speaking.
- If you are interested in finding out about speaking opportunities join the #cfp-room slack channel. Deadlines for talks can be found in the slack channel and in the master MayaData events spreadsheet.
- If you want help building out a talk, coming up with ideas for a speaking opportunity, or have a customer interested in speaking start an issue in the community project using the CFP submissions template and tag any associated event issues. Complete as much info as possible and we will ping you with next steps. We are happy to help in anyway we can, including public speaking coaching.
- If there is an event you would like to attend, are attending, speaking, or have proposed a talk and you would like support from MayaData to attend this event the process goes as follows:
- If you are presenting work from your peers, contact them for approval and guidance.
- Contact your manager for approval to attend/ speak.
- After getting approval from your manager to attend, add your event/ talk to the #cfp-room and request for approval from the Marketing team.
- Get your talk reviewed by a technical panel in the #cfp-room prior to submitting. This can avoid duplicate talks being submitted as well as enhance the proposals.
- If your travel and expenses are not covered by the conference, MayaData will cover your expenses (transportation, meals and lodging for days said event takes place). If those expenses will exceed $500, please get approval from your manager. When booking your trip, use our travel assistance, book early, and spend as if it is your own money. Note: Your travel and expenses will not be approved until your event / engagement has been approved by the Marketing team.
- If you are speaking please note your talk in the description when you add it to the #cfp-room.
- If you are not already on the speakers page, please add yourself.
- We suggest bringing swag and/or stickers with you. Contact #marketing_openebs for info on ordering swag.
MayaData OpenSource Marketing
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes and Platform SRE’s and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations easily, and we have become open source leaders in building Kubernetes into a first-class data platform.
In line with our PLOW values, we believe in Open Source Marketing as opposed to traditional marketing.
One of our primary objectives as an open source marketer is to amplify the success of users of the open source solution and to encourage the community to view itself with pride. Because the open source community is arguably the most important thing that an open source company builds, the role of an open source marketer is critically important.
Here are some guidelines on what we think are the driving principles of a good Open Source Marketer The following owes a lot to the ever famous and far superior memo by Ben Horowitz about what makes a good product manager:
- OpenSource is the way to go
- Be where the users are
- Support Open Source communities
- Anonymous community growth is important
- All user feedback is valuable
- Focus on what users need
- Help users advance their knowledge
OpenSource is the way to go
A good open source marketer will eschew cliches and ideologies and will show how the community helps to nurture qualified leads and hence customers and partners and employees and investors and other stakeholders like the Cloud Native Computing Foundation. A traditional marketer will eschew metrics, and spout platitudes such as “there is no such thing as an open-source business model.”
Be where the users are
A good open source marketer finds users wherever they are and listens to them and asks them their opinion. For instance, a good open source marketer will follow Twitter users that talk about their domain on twitter and will try to form a relationship with them. A traditional marketer thinks social media is just a way to push content to more people. A traditional marketer assumes that users with personal email addresses are just noise and not worth listening to.
Support Open Source communities
A good open source marketer believes in investing in the open source karma of their community by supporting meet-ups and related projects however they can. A traditional marketer prefers to spend money on advertising or “lead generation.”
Anonymous community growth is important
A good open source marketer will take ownership of the success of the community as measured by usage statistics such as container pulls and also by contributions by the community in the form of blogs and tweets and also pull requests and other more technical contributions. A traditional marketer would only focus on increasing registrations via user contact information. A good open source marketer has the analytics needed to prove to everyone that the community is growing - and is able to direct the efforts of the community and the company to improve those areas in need of improvement.
All user feedback is valuable
A good open source marketer views even less than 100% positive communication with pride since it shows concern about the future of the project and this type of engagement is important for the growth of the community. A traditional marketer will try to hide any opinions that are not 100% positive about the open source project.
Focus on what users need
A good open source marketer helps engineering to remain focused on what users really need as opposed to what engineering thinks they should need. A traditional marketer complains about engineering, about the users, about competitors, and about the open source itself.
Help users advance their knowledge
Good open source marketers help users to understand and adapt to the changing technological landscape. For instance, when it comes to measuring storage performance, help users understand what are the new variables and how to evaluate and set up storage benchmarking. Traditional marketers are led around by users that do not yet understand how to evaluate container attached storage and go with their assessment.
Product Development
- The development will be focused on User Needs. The tasks will be defined in terms of usable features and not technology specifics.
- The design and implementation details will be properly documented in the GitHub. The open-source components design will be published for external reviews.
- Reviews are viewed as an integral part of the development process to foster Knowledge Sharing, Informed Decision Making and Improving Quality. The review process is governed by documented guidelines.
- The feature developer/owner is responsible for taking the feature into production - which includes making sure the CI/CD includes his/her feature testing and delivery.
- The developer will be responsible for interacting with the end-users using his/her features, helping them and gathering feedback and feeding it back into the system
Coding guidelines
- All developers should strive towards managing the highest standards of coding because at MayaData, we believe - Code is marketing
- Both for open source repositories and closed source repositories should follow commenting on the code while developing for better readability.
- Every PR is provided with detailed comments about why a change is made
Code reviews
TBD : Can we include (somehow someway) these tips? https://drive.google.com/file/d/1ROZA9yKpEa8suiqVXtPO0IJtqa95SOjE/view
Product Management
- Product management is a team sport. The new culture will encourage every employee to listen to the users and situations and contribute to the product betterment (in terms of requirement).
- User engagement is the key to defining the features being built. Even before the development starts on the features, we will have facts from the users on how they are going to use the feature.
- The product will be instrumented (like in OpenEBS Director) or the user feedback is sought to determine which features are getting used and what are the key features that can generate revenue.
- The bare minimum (near MVP) features that are possible to be implemented at the earliest given the overall company skills will be implemented.CI/CD must be part of the MVP.
- We will be open to an iterative approach of defining the top priority items based on the user feedback
- Milestones are tracked using automated tools like GitHub. The status of the milestone is derived from the data collected rather than people’s hunch
Product Support
The success of the Company and Product depends on the users. Everyone in the company is responsible for supporting the users.
- The users for the product include the open source community, partners and paying customers. Everyone in the company will work towards establishing credibility with the users.
- Everyone will have an opportunity to volunteer to be the point of contact for a day (or half a day?) for OpenEBS and StorageSIG.
- Engineers from all teams will take turns answering questions, updating users by name as we complete issues, and welcoming new users and more.
- Engineers will be evaluated in part on their work when they are the point for a day or half a day - and for their responsiveness when an issue is brought to their attention.
User Adoption Team Handbook
CEO
\
\
Sales
/ \
/ \
Account User
Reps Adoption
/ | \
/ | \
/ | \
Dev SE TAM
Ad
You will collaborate and connect with communities that love technology and open source as much as we do. You will interact with developers across the globe at conferences as well as online, and co-creates with the open source community on the most impactful projects in the ecosystem. Your focus is on generating awareness about OpenEBS and Litmus, and MayaData's other current or future Open Source projects by rolling up our sleeves, contributing to the ecosystem, and enabling others to become evangelists outside the company. Not afraid to be hands-on, you might write sample code, author client libraries, and work with strategic MayaData partners such as the heroes, users, and customers to spark and engage our developer and ops communities.
Internal Interfaces
- Marketing: external content publishing
- Sales: booking meetings
- Support: rapid triage and Engingeering engagement
- Product Management: long term resolution and Engineering engagement
Metrics
- Increased awareness as measured by marketing team
- Increased community involvement as measured by marketing team
- Increased registrations to the mayadata user portal as measured by engineering
- Reduced time to conversation on OpenEBS Lists as measured by support
- Bookings as measured by sales
Responsibilities
- Reach out to users
- Write blog posts and other articles about OpenEBS, Litmus, and specific use-cases for them.
- Respond to inquiries on social channels
- Lead coversations about how to run stateful applications on k8s
- Contribute to OpenSource projects that are relevant to the space
- Channel information back to product and engineering
- Broker conversations with Support and Engineering teams
- Reach developers with unique and engaging educational content
- Meet with users, prospects, and customers
- Conduct interviews with media
- Have fun.
User onboard audit Purpose:
Onboarding users is critical for any business or community - and especially for a project such as OpenEBS and a company such as MayaData for a number of reasons including: Limited time: Our users are busy - and they try us out typically on their own time to gain understanding and trust before using our software and software services at work Product and brand promise: OpenEBS is known as the easiest to use and deploy solution for turning Kubernetes itself into a data plane. If this capability erodes then we violate our brand promise, and disappoint users and lose their trust. Self adoption model: Unlike vendors selling technology into enterprises from a prior era - , our approach is similar to that of GitLab or Atlassian or PagerDuty or GitHub or countless others - our solution must be self adopted and used in production typically before we even speak to the user. Our entire model, from IO in the user space to the branding of the Mule for the OpenSource community to the attributes we look for and reenforce in our team, is based on self adoption. Without effective self adoption we have built the wrong company, team, product, brand and other investments and commitments.
In short, poor self adoption is an existential threat.
This narrative suggest an approach to ensuring that we continue to evolve in the direction of improved ease of self adoption via a rhythm of user onboard audits.
Proposal:
With each monthly release we will convene a cross functional team - whose members will rotate as described below - in order to perform the self adoption audit.
The specifics of the self adoption audit will evolve with experience. Each team and each sprint will add or subtract components as they feel reasonable.
In all cases, the self adoption audit will highlight, document, and prioritize areas that could reasonably be assumed to impede the self adoption of our target persona - an engineer that understands enough about Kubernetes to have adopted it or to be running software in an environment based upon Kubernetes.
The process should include everything from - how do they find out about OpenEBS and OpenEBS director to initial deployment on leading platforms to any necessary customization. Each monthly effort and team can choose to explicitly focus on particular areas however all efforts and teams should deploy on AWS and OpenShift and D2IQ (subject to change).
The team should be comprised of engineering, product, marketing, and sales stakeholders. Actual end users in the community and partners such as D2IQ can be incorporated if available as well.
While team members will inevitably be of different levels within MayaData, for the purposes of the monthly effort, the team should self organize. Likely important roles that should be assumed include: Process documentation - what are we going to do? Where are we in our validation? Platform research - what are the likely issues we may encounter - what has changed in OpenShift, AWS, and D2IQ? Naive user - who can free their mindsmind from all that they know about OpenEBS and actually do the work of trying out OpenEBS as if for the first time? Results - what did we learn, how many attempts did we make, how long did it take us to achieve success? Results integration - are all of our prioritized results on the backlog? Are there any typos in the docs or improvements to Helm charts or other items that we can fix right away, without waiting for the next release? Keep in mind that words such as docs and other instructions are often easier to change than code.
Implementation:
After review and improvement - this proposal should be implemented immediately. The total duration of each audit should be part time effort for one week per month.
The team may want to convene via a kick off meeting with a senior sponsor such as a founder or senior technical leader. During this 60 minutes meeting the purpose will be reviewed and the organization of the effort will be agreed upon. At least one member of the prior month user adoption audit will attend to answer any questions.
The team will circle back with daily stand ups. At the end of the week the team will issue their results in a 1-2 page write up. They will also walk the entire company through their process and their results as a key component of our monthly all company meeting.
They will also participate in the nomination of the next team and will send one delegate to answer questions for the next month team as well.
Roles at MayaData
Ready for an opportunity to make a substantial impact with a disruptive tech company while building your Developer Advocate career in the rapidly growing Kubernetes ecosystem? Then come and PLOW with MayaData, the leading Container Attached Storage (CAS) solution for Kubernetes called OpenEBS.
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE's and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations efficiently, and we have become open source leaders in building Kubernetes into a first-class data platform.
Location: Remote (US / Europe / India Time zones)
Typical Engineering Team
We have teams dedicated to different components / initiatives. These are similar in their structure. Sweet-spot size is 8 members, but no less than 4 and no more then 10.
Team template:
- Lead Engineer
- Engineers
- QA
Key team responsibilities include:
- Thinking about the problems, design solution/approach.
- Documenting work to be done.
- Producing code.
- Producing automated tests / unit tests.
- Reviewing produced code and tests.
- Updating technical documentation / provide enough information for adjacency team to update the doc (e.g. when documentation is maintained by Solutions team).
Chief Architect
We at MayaData believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE’s and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations easily, and we have become open source leaders in building Kubernetes into a first-class data platform.
MayaData has a diverse community of bright and passionate individuals striving to have a positive impact on the world. We’re dedicated to perfecting the art of software delivery through innovation, open source and being agile amidst chaos. As Chief Architect, you have ownership and responsibility for technical delivery of MayaData products and solutions.
Responsibilities
- Live and advocate our PLOW values.
- Disrupt, Lead and Innovate.
- Take the needs and challenges of our customers and formulate the technical roadmap and technology solution that will support their business strategies and goals.
- Contribute to the MayaData community as a speaker, author or online contributor
- Provide Technical leadership across all areas of the enterprise, to ensure delivery of exceptional technical solution
- Mentor on approach and execution of solutions, coach on technologies and establishing a team wide comprehension of solution capabilities and direction
- Ensure technical expectations of deliverables are met
- Drive engineering and architectural best practices and standards to delivery quality software solutions on time.
- Be an inspiration of innovation to fellow team members and customers
- Become a trusted and valued partner of the Leadership team
- Maintaining strong expertise and knowledge of current and emerging technologies and products
- Code! MayaData doesn’t subscribe to the “post-technical” ivory tower leadership style
Lead Engineer / Team Lead
Ready for an opportunity to make a substantial impact with a disruptive tech company while building your Developer Advocate career in the rapidly growing Kubernetes ecosystem? Then come and PLOW with MayaData, the leading Container Attached Storage (CAS) solution for Kubernetes called OpenEBS.
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE's and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations efficiently, and we have become open source leaders in building Kubernetes into a first-class data platform.
Location: Remote (US / Europe / India Time zones)
In the nutshell
Lead Engineer aka Team Lead is a core leadership role in the MayaData. You are responsible for a particular team of about 8 people, working on delivering component of the MayaData portfolio.
Team Lead is still considered a technical position. You are expected to be coding and contributing at more then 50% of your time. We don't believe in dedicated people managers on the team level as we are a strong engineering organization.
Responsibilities
Team Leadership
- Make sure, that people in the team are feeling comfortable and secure. They understand overall MayaData vision and strategy. They understand why they are working on particular features.
- Understand the gaps by involving with multiple teams in company.
- Suggest improvements and changes to the overall organization of the Engineering and your team.
- Identify metrics for various components like code quality, team productivity, motivations, culture, sessions feedback etc.
- Define goals/OKRs with and for your team.
- Help you team to learn and grow, identifying external/internal training requirements.
- Exhibit and inspire team to follow process/culture.
- Track our marketing and sales activities. Encourage participation and participate at conferences, write blog articles, tweet etc.
Project Management
- Keeping an eye on your team's JIRA and keeping it healthy.
- Project level tracking for execution completion within time.
- Lead/participate in internal project review meeting.
- Helping in risk mitigation for project execution.
- Plan team size in advance.
- Project level check for required E2E coverage.
- Make sure that we follow team's definition of done.
Product Owner
- Agrees with Product Manager on the overall priorities, and define together the intended content for upcoming releases.
- Works closely with the Product Manager and organizes grooming sessions anytime there is a need for discussion over items in backlog. Grooming sessions takes place regularly with intervals between 2 and 4 weeks.
- Convert Stories to backlog Epics and Tasks. Participate at grooming sessions with Product Management.
- Be a close partner to Product Management organization to identify new initiatives, improve existing features and mitigate issues our customers may be facing.
- Prioritize work for team according to agreed priorities with Product Management and the overall company goals and vision.
- Understand market trends on technologies, products. Research competitive solutions.
- Keep our persona needs on your mind. Proactively suggest changes to features or add new ones to backlog for discussion with Project Management.
- Always make sure, that you know why we are building something, so you can explain to your colleagues.
Technical Management
- Learn new technologies and train the team. Allow other colleagues in your team to spend time on learning and playing with new technologies.
- Listen to new learnings from company and guide them on choosing one that match our requirements.
- Motivate team in writing skills like blogs, white papers etc.
- Always question the status quo -- cannot we automate some step in the process, cannot we use different approach to some tasks (e.g. how we do CI/CD, how we do generate documentation etc.).
- Promote and keep eye on the proper code-review techniques.
Customer/User Engagement
- Make sure required trainings happened with support team.
- Make sure dev/E2E teams have enough time in their tasks by empowering support team in solving user/customer issues.
- Avoid any escalations from customers with timely and apt response.
- Being active and leading few interested feature areas in other related open-source projects.
Backend Engineer
Ready for an opportunity to make a substantial impact with a disruptive tech company while building your Developer Advocate career in the rapidly growing Kubernetes ecosystem? Then come and PLOW with MayaData, the leading Container Attached Storage (CAS) solution for Kubernetes called OpenEBS.
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE's and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations efficiently, and we have become open source leaders in building Kubernetes into a first-class data platform.
Location: Remote (US / Europe / India Time zones)
Responsibilities
- Develop features and improvements to the MayaData Open Source and Enterprise products in a secure, well-tested, and performant way.
- Keep tickets updated, make sure that they cover work being done.
- Owning a project/feature from concept to production, including proposal, discussion, execution, roll-out plans, helping the support team to have good article/blog/doc, helping e2e team with test plans.
- Participate in the proper code-reviews.
- Collaborate with Users (Community and Customers), Product Management and other stakeholders within Engineering (frontend, UX, etc.) to maintain a high bar for quality in a fast-paced, iterative environment.
- Advocate for improvements to product usability, quality, security, and performance.
- Solve technical problems of moderate scope and complexity.
- Craft code that meets industry and open source standards for style, maintainability, and best practices for a high-scale Data Center platform and tools. Maintain and advocate for these standards through code review.
- Recognize impediments to our efficiency as a team ("technical debt"), propose and implement solutions.
- Represent MayaData and its values in public communication around specific projects and community contributions.
- Confidently ship small features and improvements with minimal guidance and support from other team members. Collaborate with the team on larger projects.
Backend Engineer Levels
Junior (or Intern) Backend Engineer
Backend Engineer Interns share the same requirements and responsibilities outlined above, but typically join with less or alternate experience than a typical Backend Engineer.
Backend Engineer
As described above.
Senior Backend Engineer
The Senior Backend Engineer role extends the Backend Engineer role.
Responsibilities
- Advocate for improvements to product quality, security, and performance that have a particular impact across your team.
- Solve technical problems of high scope and complexity.
- Exert influence on the overall objectives and long-range goals of your team.
- Actively participate at product grooming sessions. Help Lead Engineer to drive their area of responsibilities.
- Experience with performance and optimization problems, particularly at large scale, and a demonstrated ability to both diagnose and prevent these problems
- Help to define and improve our internal standards for style, maintainability, and best practices for operating in a high-scale Kubernetes environment. Maintain and advocate for these standards through code review.
- Represent MayaData and its values in public communication around broader initiatives, specific projects, and community contributions.
- Provide mentorship for Junior and Intern Engineers on your team to help them grow in their technical responsibilities and remove blockers to their autonomy.
- Confidently ship moderately sized features and improvements with minimal guidance and support from other team members. Collaborate with the team on larger projects.
- Confidently helps the community users and customers with the product or feature with minimal guidance and support from other team members.
Requirements
- Computer science education or equivalent experience.
- Each Backend Engineer will be expected to be an expert with one primary product or functionality lead or components based on the professional experience and role.
- Significant professional experience with the language required by the expertise or specialty. The dominant languages are Go, Java, Python, Rust, C/C++, JavaScript depending on the area of expertise.
- Professional experience with any other technologies that may be required by the expertise or specialty.
- Proficient in the microservices architecture, ability to debug microservices, ability to explain and understand concepts around Kubernetes, DevOps and Data Management.
- Proficiency in the English language, both written and verbal, sufficient for success in a remote and largely asynchronous work environment.
- Demonstrated capacity to clearly and concisely communicate about complex technical, architectural, and/or organizational problems and propose thorough iterative solutions
- Experience with usability, performance and optimization problems and a demonstrated ability to both diagnose and prevent these problems
- Experience owning a project from concept to production, including proposal, discussion, and execution. Ability to work single-handed as well as in a team.
- Ability to use MayaData Products.
The following are considered a plus:
- Experience working with a global, remote team or otherwise multicultural team.
- Passionate about working for Infrastructure Products focused on Storage and/or Kubernetes SREs.
- Passionate about/experienced with open source and developer tools.
- Contributions to other open-source projects.
Frontend Engineer
Ready for an opportunity to make a substantial impact with a disruptive tech company while building your Developer Advocate career in the rapidly growing Kubernetes ecosystem? Then come and PLOW with MayaData, the leading Container Attached Storage (CAS) solution for Kubernetes called OpenEBS.
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE's and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations efficiently, and we have become open source leaders in building Kubernetes into a first-class data platform.
Location: Remote (US / Europe / India Time zones)
Responsibilities
- Develop features and improvements to the product in a well-tested and performant way.
- Develop features that meet the internationalization and localization best practices/standards.
- Develop UI that supports white labeling.
- Experienced in instrumenting the product to help with AB testing of new features.
- Participate in the proper code-reviews.
- Work with Product Management and other stakeholders (Backend, UX, etc.) to iterate on new features.
- Craft code that meets our internal standards for quality, style, maintainability, and best practices for a high-scale web environment. Maintain and advocate for these standards through code review.
- Confidently ship small features and improvements with minimal guidance and support from other team members. Collaborate and guide your team on larger projects.
- Help improve the overall experience of our product through improving the quality of the Frontend features both in your and other teams.
- Help identify areas of improvements in the code base, both specific to your team and outside your team (eg. component library) and help in contributing back to make it better
- Fix prioritized issues from the issue tracker.
- Advocate for improvements to product quality, security, and performance that have particular impact across your team.
- Solve technical problems of high scope and complexity.
- Exert influence on the overall objectives and long-range goals of your team.
- Experience with performance and optimization problems, particularly at large scale, and a demonstrated ability to both diagnose and prevent these problems.
- Represent MayaData and its values in public forums and conferences around broader initiatives, specific projects, and community contributions.
- Provide mentorship for junior engineers in your team to help them grow in their technical responsibilities.
Frontend Engineer Levels
Intern Frontend Engineer
Intern Frontend Engineers, while sharing the same requirements and responsibilities outlined above, typically join with less or alternate experience than typical Frontend Engineers.
Junior Frontend Engineer
Intermediate Frontend Engineers are expected to meet the requirements and execute the responsibilities with minimal assistance.
Frontend Engineer
As described above.
Senior Frontend Engineer
The Senior Frontend Engineer role extends the Frontend Engineer role. Additional responsibilities include:
- Advocate for improvements to product quality, security, and performance that have particular impact across your team.
- Solve technical problems of high scope and complexity.
- Exert influence on the overall objectives and long-range goals of your team. This could be technical and/or product focused.
- Actively participate at product grooming sessions. Help Lead Engineer to drive their area of responsibilities.
- Experience with performance and optimization problems, particularly at large scale, and a demonstrated ability to both diagnose and prevent these problems
- Help to define and improve our internal standards for style, maintainability, and best practices for a high-scale web environment.
- Represent MayaData and its values in public communication around broader initiatives, specific projects, and community contributions.
- Provide mentorship for Junior and Intermediate Engineers in your section to help them grow in their technical responsibilities and remove blockers to their autonomy.
- Confidently ship moderately sized features and improvements with minimal guidance and support from other team members. Collaborate with the team on larger projects.
- Improves the engineering projects at MayaData via maintainer trainee program at own comfortable pace, while striving to become a project maintainer.
Requirements
- Professional experience with at least one modern JavaScript web MVC framework/library (React, Angular, Ember, VueJS).
- Experience with UI automation test frameworks (eg. Selenium, cypress, Jest).
- Experience using Git in the workplace environment.
- A solid understanding in core web and browser concepts (eg. how HTTP protocol works, what are the verbs, etc.).
- A solid understanding of HTML, CSS, and core JavaScript concepts.
- A solid understanding of REST principles.
- Proficiency in the English language, both written and verbal.
- Demonstrated capacity to clearly and concisely communicate about complex technical, architectural, and/or organizational problems and propose thorough iterative solutions.
- Experience with performance and optimization problems and a demonstrated ability to both diagnose and prevent these problems
- Comfortable working in a highly agile, intensely iterative software development process.
- Demonstrated ability to onboard and integrate with an organization for a long-term.
- Positive and solution-oriented mindset.
- Effective communication skills: Regularly achieve consensus with peers and clear status updates
- Self-motivated and self-managing.
- Demonstrated ability to work closely with other parts of the organization.
- Ability to thrive in a fully remote organization.
The following are considered a plus:
- Experience working with a global, remote team or otherwise multicultural team.
- Experience in a high-performance organization, preferably a tech startup.
- Experience contributing to open-source software.
- Experience working as part of cloud-native solutions.
- Domain knowledge of Kubernetes and/or storage.
Principal Software Engineer
Ready for an opportunity to make a substantial impact with a disruptive tech company while building your Developer Advocate career in the rapidly growing Kubernetes ecosystem? Then come and PLOW with MayaData, the leading Container Attached Storage (CAS) solution for Kubernetes called OpenEBS.
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE's and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations efficiently, and we have become open source leaders in building Kubernetes into a first-class data platform.
Location: Remote (US / Europe / India Time zones)
In the nutshell
You will work under minimal direction to design and develop high performance storage algorithms for the next generation of NVMe over Fabrics storage solutions in containers for containers. This is an opportunity to own critical algorithms that must be invented to match the performance of next generation solid state storage technologies. The Principal Engineer must have the ability to discuss and analyze abstract algorithms with the team to evaluate and refine the design prior to implementation. Additionally, the Principal Engineer will be responsible for translating the design to an implementation in Rust/C/C++ with a clear understanding of practical system issues. The Principal Engineer will have the technical ability to write functional specs as well as responding to requirement documents and system level test plans, propose design changes and suggestions to team, collaborate with engineers and other product groups as needed cross functionally.
We’re looking for a deeply skilled Principal Software Engineer to work closely with the product and the open source community to build the Mayadata vision. You'll join a highly collaborative team working along with talented engineers focusing to be the best in Container Attached Storage.
Role Description:
- System engineering and implementation in Rust and C.
- Working on performance issues using creative experiments and internally developed product features.
- Research, propose, and integrate relevant open-source projects based on product objectives.
- Write organized, efficient, and well documented Rust and C/C++ code as an example for junior engineers.
- Participation in all levels of product definition, design, implementation, testing, and deployment.
- Must include the ability to discuss abstract system architectures from ideas through implementation and creatively apply domain experience to solve technical challenges.
- Mentoring software engineers, fostering an environment of trust and accountability.
Requirements:
- Programming experience collaborating on software development Open Source Community.
- Programming in C or C++ or Rust, or other systems programming languages.
- Capable of meeting tight deadlines with excellent overall project and product development life cycle experience and team spirit.
- Experience in agile and scrum methodologies.
- Linux OS internals experience.
- Experience in functional programming.
Nice-to-have:
- Linux OS internals experience.
- Expert level Rust/C/C++ coding and debugging; kernel, protocol, or hardware programming.
- Shell scripting and knowledge in python.
- Experience with Linux file system, block layer.
- Experience with storage protocols SCSI, NVMe.
- Strong technical background with both the ability and desire to continuously improve the overall storage software product, in terms of quality, features, and design.
- Able to maintain in-depth understanding of industry trends in computer system hardware, current and future storage and networking protocols, and software algorithms in distributed systems, data encoding and transmission, and performance; Areas of focus include NVMe, NVMe over Fabrics, persistent memory, RDMA and TCP network protocols, kernel bypass, data encoding and compression/deduplication.
- Expert level understanding of computer hardware, algorithm, and protocol performance, with experience in profiling and root causing performance issues.
- Experience with I/O, memory, and compute performance limitations.
System Engineer
Ready for an opportunity to make a substantial impact with a disruptive tech company while building your Developer Advocate career in the rapidly growing Kubernetes ecosystem? Then come and PLOW with MayaData, the leading Container Attached Storage (CAS) solution for Kubernetes called OpenEBS.
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE's and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations efficiently, and we have become open source leaders in building Kubernetes into a first-class data platform.
Location: Remote (US / Europe / India Time zones)
In the nutshell
Building the fastest open source, block storage system in the world isn't easy. The Engineering Division at Mayadata is set out to build the next generation of highly performant, and resilient block storage software, in an open source environment.
We’re looking for deeply skilled systems engineers who can work on Linux/Windows and love to program in C and Rust, to work closely with the product and the open source community to build the Mayadata vision. You'll join a highly collaborative team working along with talented engineers focusing to be the best in Container Attached Storage.
Responsibilities
- Contribute to the design and implementation of the Mayastor data engine written in Rust.
- Work with a combination of open and closed source developer tools technologies.
- Leverage SPDK, SPDK, NVMe, CSI, & Linux internals.
- Leverage your outstanding collaboration and communication skills to partner with internal teams on their direction, priorities, and guidance around Rust best practices.
Requirements
- Rust programming language & Tools
- Data Plane Development Kit (DPDK) and the Storage Plane Development Kit (SPDK) which are written in C
- Would love to work with technologies like NVMe, virtio and lockless algorithms
- Prior experience with debuggers, profilers, or symbol format development
- Understanding and knowledge of Linux and/or Windows operating systems and runtime concepts
- Ability to demonstrate a growth mindset and flexibility to adapt to changing goals and priorities
- Experience troubleshooting and debugging issues
- Strong customer focus and passion for shipping commercial software
Basic Qualifications
- 3+ years programming experience collaborating on software development Open Source Community.
- 3+ years programming in C, C++. Interested in Rust.
- Interested in technologies like DPDK.
Preferred Qualifications
- Experience of Linux, C development and integration and testing.
- Interest in working with Rust.
- Excellent knowledge of Multithreading.
- Basic knowledge in Linux/BSD/Solaris file system and or Block layer.
- Basic knowledge in Storage protocols SCSI & NVMe.
- Expertise in designing, developing software.
- Experience in Agile and Scrum methodologies.
- Capable of meeting tight deadlines with excellent overall project and product development life cycle experience and team spirit.
Test Engineer
Ready for an opportunity to make a substantial impact with a disruptive tech company while building your Developer Advocate career in the rapidly growing Kubernetes ecosystem? Then come and PLOW with MayaData, the leading Container Attached Storage (CAS) solution for Kubernetes called OpenEBS.
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE's and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations efficiently, and we have become open source leaders in building Kubernetes into a first-class data platform.
Location: Remote (US / Europe / India Time zones)
In the nutshell
Testing is the first-class citizen in MayaData. Our customers and users relay on us to keep their data safe and accessible. On the other hand, we write software and software has a tendency to contain bugs. Role of the test engineering is to help discovering them early in the process.
Responsibilities
- Develop and maintain tooling for running end-to-end tests of MayaData products.
- Keep tickets updated, make sure that they cover work being done.
- Purposefully break things, deep-dive into the inner workings of storage components.
- Be comfortable not to stick on the happy path. Actively seek edge-cases.
- Detailed understanding of how to properly document test cases and create effective and focused testing plans.
- Owning a project/feature from concept to production, including proposal, discussion, execution, roll-out plans, helping the support team to have good article/blog/doc, helping test team with test plans.
- Participate in the proper code-reviews.
- Collaborate with Users (Community and Customers), Product Management and other stakeholders within Engineering (frontend, UX, etc.) to maintain a high bar for quality in a fast-paced, iterative environment.
- Craft code that meets industry and open source standards for style, maintainability, and best practices for a high-scale Data Center platform and tools. Maintain and advocate for these standards through code review.
- Recognize impediments to our efficiency as a team ("technical debt"), propose and implement solutions.
- Represent MayaData and its values in public communication around specific projects and community contributions.
- Confidently ship features and improvements with minimal guidance and support from other team members. Collaborate with the team on larger projects.
Requirements
- Computer science education or equivalent experience.
- Significant professional experience with the language required by the expertise or specialty. The dominant languages are Go, Rust, JavaScript/TypeScript, Python, C/C++, depending on the area of expertise.
- Experience with Linux command line and scripting. Ability to read system logs and do basic troubleshooting.
- Experience with debugging, tracing and profiling tools.
- Professional experience with any other technologies that may be required by the expertise or specialty.
- Proficiency in the English language, both written and verbal, sufficient for success in a remote and largely asynchronous work environment.
- Demonstrated capacity to clearly and concisely communicate about complex technical, architectural, and/or organizational problems and propose thorough iterative solutions.
- Experience owning a project from concept to production, including proposal, discussion, and execution. Ability to work single-handed as well as in a team.
- User level knowledge of Kubernetes.
- Ability to use MayaData Products.
The following are considered a plus:
- Experience with some CI/CD tooling (Jenkins, GitLab pipelines, GitHub actions).
- Experience with mutation testing and fault injection systems.
- Experience working with a global, remote team or otherwise multicultural team.
- Passionate about working for Infrastructure Products focused on Storage and/or Kubernetes SREs.
- Passionate about/experienced with open source and developer tools.
- Contributions to other open-source projects.
Community Manager
Ready for an opportunity to make a substantial impact with a disruptive tech company while building your Community Manager career in the rapidly growing Kubernetes ecosystem?
Ready for an opportunity to make a substantial impact with a disruptive tech company while building your Developer Advocate career in the rapidly growing Kubernetes ecosystem? Then come and PLOW with MayaData, the leading Container Attached Storage (CAS) solution for Kubernetes called OpenEBS.
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE's and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations efficiently, and we have become open source leaders in building Kubernetes into a first-class data platform.
Location: Remote (US / Europe / India Time zones)
Role description
As a MayaData Developer Community Manager, you will have the exciting opportunity to help drive the growth and shape the future of OpenEBS and Kubernetes through building a vibrant contributor community. MayaData Developer Community Team aims to build an amazing community where all OpenEBS and Kubernetes users can thrive.
We are looking for a community manager to grow our community exponentially through close interaction with different internal stakeholders, the different community programs, and our global community.
Responsibilities
- Build out and execute on the community vision together with internal and external stakeholders.
- Represent MayaData in the developer community and help to build a welcoming, inclusive, and supportive community environment for members from a variety of backgrounds.
- Develop and execute on timelines, deliverables, and reporting for your goals to drive success against team goals.
- Build and execute strategic plans for growing the community in target regions around the world.
- Manage event logistics and content flow to ensure maximum impact.
- Contribute to improvements in internal processes and procedures as our team grows and matures.
- Take a data-driven approach to problem-solving.
Requirements
- Great at fostering and building relationships both in-person and online at scale.
- A great communicator with emotional intelligence for developers and understand their needs.
- A conduit between the company and the community and can discover ways to serve both.
- Good at seeing the big picture and understanding how the smaller things fit together to achieve this big picture.
- Has partnered effectively with marketing teams to drive growth.
- Have successfully grown a developer community.
- Good interpersonal and collaboration skills.
- Experience with managing and scaling community programs.
- Empathy for developers, regardless of skill level.
- Strong written and verbal communication skills.
Pluses
- Project management experience.
- Experience with technical writing.
- Previous remote working experience.
Sound like an opportunity where you would thrive and grow? More importantly, could this be the right next step in reaching your career goals? Reach out to us and let’s explore whether this role is the right fit for you.
Customer Success
Overview
We at MayaData believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE’s and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations easily, and we have become open source leaders in building Kubernetes into a first-class data platform.
Customer Success is an important function at MayaData in the broader goal of achieving customer satisfaction.
As customer success engineers and architects, you are driven to make every customer, a reference customer; enable customers must grow their usage of our open source and commercial software and services substantially over time.
As customer success engineers and architects, you will collaborate with other departments in the organization to provide the best experience for our customers.
Customer Success Engineers directly interact with customers to help them quickly solve their problems and ensure customer satisfaction remains high.
Some of the essential skills required by Customer Success Engineers are:
- You share our PLOW values - especially learning, openness and a sense of ownership.
- Being Empathetic: People in customer success roles should genuinely want to help other people. That desire begins with empathy: the willingness to understand another person’s experience and see it through their eyes. One proof of empathy is the ability to express the user’s needs in one’s own words.
- Strong communicator: This job is about communicating with other people. Customer Success Engineers need to communicate well both verbally and in writing. Communication is about listening, then clearly articulating ideas and information in an authentic way.
- Master of simplicity: When a customer makes the effort to reach out and ask for help, it’s the Customer Success Engineer’s job to quickly assess the problem, sort it all out, and then present the customer with the simplest answer possible.
- Growth mindset: Products, technology, and policies will change over time, and Customer Success Engineers will need to change with them.
- Always learning: Customer Success Engineers consistently demonstrate a drive for learning and growing. Strong inclination to certify yourself with latest Kubernetes certification such as CKA
Customer Success teams directly report to the Chief Operations Officer - COO, who ensures that the Customer Success teams are highly motivated and aligned to the Organizational goals.
Levels of Customer Success Engineers
As a customer success engineer, you will be responsible for users and customers of MayaData products are getting the best experience when they need support. At MayaData, we believe that users self adopt the projects and technology we build and eventually many of them require our support to scale their usage of Kubernetes as a data layer and to maintain their use of MayaData software and services production. As a customer success engineer, you provide an excellent experience to end-users, field teams, and the engineering team during this process.
Junior Customer Success Engineer
- This is the team’s entry-level role. We look for people with potential, who have 0-2 years of experience helping customers in some capacity, and who possess essential customer support skills.
- Associates are in training and need guidance to perform at the standard level set for customer success engineers.
- The individuals in this role are well versed in the concepts and have undergone the OpenEBS training and workshop.
- The individuals in this role are expected to help customers by pointing in the right direction with the help of Documentation or KB articles, helping them navigate through OpenEBS and other products from MayaData.
- The individuals are expected to become comfortable with tools like Slack and ZenDesk and help with ensuring the customer tickets are updated.
- People are usually in this role for at least 3 months before becoming full-fledged Customer Success Engineers
Customer Success Engineer
- Expert knowledge on Linux (Centos, Ubuntu, Debian, RedHat) with at least 1-2 years experience in system administration and support role.
- Customer Success Engineers have gained experience in installing the OpenEBS and other products from MayaData.
- Customer Success Engineers have the ability to determine the components that are potentially causing an issue.
- Customer Success Engineers are comfortable editing and updating the OpenEBS and Kubera documentation based on the interactions with the customers.
- Customer Success Engineers are the first point of contact for all incoming customer issues. These engineers handle all incoming chats and phone calls. This is where all incoming tickets are triaged and then routed to the appropriate team.
- Customer Success Engineers are expected to provide an initial response to issues within 15 minutes and resolve the issues within 30 minutes of being assigned. If a customer issue is more complex and requires more time to resolve, it’s assigned to Developer Advocate handling the feature.
- Be the driver for customer support calls and make sure that customers get the best experience.
- All the communication between the customer and the MayaData team should be documented in the ticketing system.
- Convert the tickets into relevant content in the MayaData help center through the troubleshooting and solution guides.
- Escalate the tickets to the next level if it doesn’t meet the SLA.
- Prepare, review, and maintain technical document. Ability to gather and analyse product information from various sources to document new or update exisiting documents.
- Inclination towards getting CKA/CKAD certified.
Lead Customer Success Engineer
In addition to the responsibilities defined above:
- Lead Customer Success Engineer must demonstrate that they can proactively identify problem areas and mentor and train other Customer Success Engineers on how to solve more difficult issues.
- They often specialize in one or more product areas and are considered experts in those areas.
- Leads are responsible for identifying the issues that are causing pain to the customers and are causing the customers to drop off. The issues need to be escalated to the Product Management team.
- Leads have the ability to learn about customer deployment and reproduce it internally.
Engineering Manager - Customer Success
Customer Success Engineering manager is comfortable with all the responsibilities of a lead Customer Success Engineers and can play the role of the support engineer when the situation demands.
Customer Success Engineering Managers must believe that a great overall Customer Success experience can be achieved by being as concerned with the Customer Success Teams’ experience as you are with the customer experience. In short, happy teams equals happy customers.
- Hire and manage world-class customer success engineers and architects to run 24x7 support operations. Require strong people and project management skills. They need to build relationships, manage performance, and deliver on their commitments.
- Ensure that every customer becomes a reference customer; customers must grow their usage of our open source and commercial software and services substantially over time.
- Relentlessly advocate for the customer - taking the perspective that their success comes first; it isn’t only about whether they know how to run MayaData product A or B correctly, it is about whether they succeed in their use of Kubernetes as a data layer.
- Provide continuous training on OpenEBS and surrounding technologies to the support team to keep them updated with the frequent product releases.
- Be the driver for important customer support calls and make sure that customers get the best experience.
- Continuously improve the customer support process by seeking feedback from customers, field engineers, and developers.
- Drive the development of the content in the MayaData help center through the troubleshooting and solution guides.
- Tune and set up the backend support tools such as ZenDesk and Slack for driving support team productivity. Point of contact for support escalations.
- Train the support team to be self-sufficient.
- Develop and publish the metrics around customer success to the internal team at regular intervals. Are concerned with many other essential customer service metrics such as first reply time, first contact resolution, handle time, and so on.
- Be part of the bug triage with engineering and product management to help drive the prioritization of customer issues to achieve excellence in customer success.
- CSAT and ESAT surveys are taken to address concerns from both customers and employees.
Key Skills for this role are:
- Communication - You communicate well by building relationships based on trust and respect.
- Direction setting - Building healthy relationships helps you set direction by telling the story of where you’re going and why
- Motivating and recognizing - Building healthy relationships helps you set direction by telling the story of where you’re going and why
- Change management and removing roadblocks - You manage change effectively by using critical thinking to re-design better processes, get buy-in, train people, align everyone’s behavior to those new processes.
- Conflict management, feedback, and development - You handle difficult conflicts on the team by giving tough, fair, but direct feedback.
- Hiring, onboarding, and diversity - Build your team with a lens on diversity and inclusion by hiring great talent and onboarding them well.
Architect - Customer Success ( aka Field Technologist)
The difference between a Customer Success Engineer and an Architect is experience, subject matter expertise and technical mastery, and their influence in the organization. They’re expected to provide guidance and best practices for providing excelling support for their areas of product expertise. They are trainers and mentors for both customers as well as customer success engineers.
- Customer Success Architects have mastered multiple parts of the product and, operate as liaisons to the Product Management and Development teams, help each of those teams understand where the product can be improved and how
- Customer Success Architects are excellent at communicating complex customer issues to software development teams and can make suggestions for improving the product and influencing the product roadmap.
- Leading developer and user advocacy including coordinating the ever-increasing amount of content being created by the OpenEBS community including MayaData employees and others.
- Personally delivering talks, solution guides, blogs and other forms of communication to help in explaining the benefits and technologies of a container attached storage, OpenEBS, and MayaData software and services.
- Testing scenarios as and Being a first customer shipped for releases of OpenEBS and MayaData software - and demanding a quality-first approach to software that has progressed from the alpha stage into beta and then production quality.
- Delivering ad-hoc projects with partners and MayaData engineers as needed, working with existing solutions and product engineering resources.
- Collaborating with other engineers to develop reference architectures for running a variety of stateful applications in Kubernetes.
Key Skills:
- Must be an experienced software / DevOps engineer who also understands storage and data management and who has experience in explaining technical solutions to a range of personas including storage engineers, open-source developers, SREs, and operations and application architects.
- Experience in assisting enterprises with architecting systems running stateful workloads on or with containers is required.
- A passionate interest in better approaches to improving an enterprise’s capabilities to build and operate stateful workloads is required.
- Experience in storage performance management and in sizing large storage environments for enterprises extremely helpful.
- Design architecture, and development experience in a large software project (internal or open-source) required.
Senior Architect - Customer Success ( aka Chief Field Technologist)
In addition to the responsibilities defined for Architect - Customer Success, Senior Architects will help with:
- Advocating within the community and within MayaData for the development of capabilities that help users do the jobs they need to do including achieving data agility by running stateful workloads on Kubernetes. Leverage social networks, blog and video platforms, and highly scalable marketing technologies to get the word out.
- Partnering with Sales leadership for “meetings that move the needle” with senior leaders in key accounts
- Positioning and highlighting MayaData and its employees as a technical thought leader, both online and offline
Key Skills:
- Experience leading initiatives in transformation (Cloud migration, Storage migration, DevOps or Agile)
- Aware of industry trends in order to gain a deeper product understanding
- Experience writing books, developing video content, and/or speaking to large audiences is required.
Hiring Process
All interviews are conducted using Zoom video conferencing software or Google Hangouts or in person. To learn more about someone conducting your interview, find their job title on our team page.
Please keep in mind that you can be declined at any stage of the process. You should consider each of the following bullets as though the words, "If selected" precedes them.
- You will receive a technical questionnaire to complete.
- You will be invited to schedule a 30 minute screening call.
- You will discuss your technical skills for 60 minutes with a member of the Customer Success team.
- You will have 2-3, 45 minute team interviews with at least one Lead Customer Success Engineer.
- You will talk for 60 minutes with a Customer Success hiring manager.
It's possible you may have additional 60 minute interviews with the Directors of Infrastructure Engineering, Engineering, User Adoption, Product Management depending on the Level of the role.
If approved, you will subsequently be made an offer.
Additional details about our process can be found on our hiring page.
We are an equal opportunity employer and value diversity and inclusion at our company. We do not discriminate on the basis of race, religion, color, national origin, gender, sexual orientation, age, marital status, veteran status, or disability status.
Developer Advocate
Ready for an opportunity to make a substantial impact with a disruptive tech company while building your Developer Advocate career in the rapidly growing Kubernetes ecosystem? Then come and PLOW with MayaData, the leading Container Attached Storage (CAS) solution for Kubernetes called OpenEBS.
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE's and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations efficiently, and we have become open source leaders in building Kubernetes into a first-class data platform.
Location: Remote (US / Europe / India Time zones)
Role description
As a MayaData Developer Advocate you will have the exciting opportunity to help drive the growth and shape the future of OpenEBS and Kubernetes through building a vibrant contributor community. In this highly technical role, you will be an ecosystem influencer and champion of users’ needs. You will work to build relationships and deeply understand and improve people’s adoption journeys by driving a range of activities, including inspiring users with the latest technology advancements (such as Chaos Engineering and Kubera), operational best practices, integrations with other open source projects, and identifying and removing the friction points getting in their way.
Responsibilities
- Connect online and face-to-face with user group members to build personal relationships and deeply understand their needs, usage, journeys, and barriers to adoption
- Produce high quality technical “how-to” content (blogs, webinars, talks) addressing common user needs, latest technology advances, and emerging best practices
- Present at meetups, conferences, and other ecosystem events
- Build and nurture relationships with fellow ecosystem influencers and open source leaders
- Support our user group through regular office hours and community slack channels
- Monitor user group growth and health, tracking metrics and running regular user groupsurveys
- Seek out an understanding of the friction points getting in users’ way and launch & own programs to remove them
- Blogging, learning, trying, hacking, demonstrating, documenting, instrumenting, educating, speaking, advocating!
- Promote our real users making them the stars
- Proactively use Twitter and other social media channels to share your ideas and grow your ecosystem influence
Requirements
- 5 years of Operations, SRE, or System Administration experience
- Experience using and contributing to open source software
- Experience using Linux (your favorite window is a terminal)
- Experience developing for or operating Kubernetes or similar modern orchestration environments
- Excellent interpersonal and communication skills
- Positive attitude and the ability to be proactive, resourceful and flexible
- Desire to collaborate with, learn from, and inspire others
- Ability to work as a self-starter with minimal guidance
- Continual learner who thrives on figuring out new technology
- A bias for action with an ability to iterate rapidly to produce results
- Previous experience working in early stage company
- Willingness to be put on display taking others with you down your learning path (messing up on screen is ok)
Sound like an opportunity where you would thrive and grow? More importantly, could this be the right next step in reaching your career goals? Reach out to us and let’s explore whether this role is the right fit for you.
Technical Account Manager
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE’s and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations easily, and we have become open source leaders in building Kubernetes into a first-class data platform.
The Role
The Technical Account Manager is the liason between the customer and MayaData. The TAM owns the account relationship. The TAM is responsible for making sure that the customer is using the product successfully, and to its full potential. After the initial onboarding, the TAM is responsible for:
- Grow the Account
- Introduce new products, features, etc. to the customer
- Trainin new users of MayaData products so they can get the most out of the tools
- Own customer relationship and be a trusted advisor to them
- Maintain Customer Success Plan KPIs
- Perform Periodic Health Checks
- Advocate for Customer Needs within Engineering and other depts
- Manage escallations, support ticket backlog, etc.
Technical Marketing Engineer
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE’s and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations easily, and we have become open source leaders in building Kubernetes into a first-class data platform.
The Role
The Technical Marketing Engineer is the role which needs focus on marketing as well as product strategy.The TEM will work in close relation to solutions, engineering, product, sales, executive, and marketing teams to make tangible to users, customers, and partners the benefits delivered by our products. After the inital onboarding, the TEM is responsible for
- Creating different possibilities with our products and other solutions in the Kubernetes ecosystem
- Solving the real needs of users
- Marketing the product for huge outreach
- Approaching for potential end-users and for prioritizing their needs in our products
- Maintaining the existing customer relationships
Technical Writer
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud- native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE’s and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations easily, and we have become open source leaders in building Kubernetes into a first-class data platform.
Requirements:
- Grown up in a primarily English speaking location, or recently have spent 2 years in an English-speaking location doing full immersion learning
- Curious about people and technology and how people use technology to get things done
- A sample of work (at least two articles or pieces of content) that they can share as part of a portfolio
- Willing to spend 30 minutes discussing the work with an interviewer
- Willing to learn about a technical subject that they’re unfamiliar with, and explain the subject back to their teacher
- Comfortable with morning meetings, to accommodate time zone differences
- Internet access, and is comfortable working at a remote-first company
Nice-to-haves
- An interest in open source or software development
- Some interest in technical marketing or technical communication
- Some understanding of SEO and related concepts
- Starting their career, or looking for a switch in careers
Responsibilities:
- Write and rewrite technical content having to do with the use of Kubernetes as a data layer and related themes
- Lead efforts to solicit content from community users, partners, and the MayaData team
- Embrace and build upon the company values - summarized as PLOW
Solution Engineering
Overview
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE’s and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations easily, and we have become open source leaders in building Kubernetes into a first-class data platform.
Requirements
- Share our values, and work in accordance with those values
- Positive and solution-oriented mindset
- Effective communication skills: Regularly achieve consensus with peers, and clear status updates
- An inclination towards communication, inclusion, and visibility
- Self-motivated and self-managing, with strong organizational skills.
- Demonstrated ability to work closely with other parts of the organization
- Demonstrated ability to onboard and integrate with an organization long-term
- Ability to thrive in a remote-first organization
- Comfortable working in a highly agile, intensely iterative software development process
- Computer science education or equivalent experience.
- Each Solution Engineer will be expected to be an expert with one or more platforms and workloads based on the professional experience and role.
- Professional experience with any other technologies that may be required by the expertise or specialty.
- Proficient in the microservices architecture, ability to debug microservices, ability to explain and understand concepts around Kubernetes, DevOps and Data Management.
- Proficiency in the English language, both written and verbal, sufficient for success in a remote and largely asynchronous work environment
- Demonstrated capacity to clearly and concisely communicate about complex technical, architectural, and/or organizational problems and propose thorough iterative solutions
- Experience with usability, performance and optimization problems and a demonstrated ability to both diagnose and prevent these problems
- Experience owning a project from concept to production, including proposal, discussion, and execution. Ability to work single-handed as well as in a team.
- Ability to use MayaData Products - OpenEBS, Litmus and Kubera
Nice-to-haves
- Experience in a peak performance organization, preferably a tech startup.
- Experience with the MayaData products - OpenEBS, Litmus, Kubera as a user or contributor
- Experience working with a global, remote team or otherwise multicultural team
- Passionate about working for Infrastructure Products focused on Storage and/or Kubernetes SREs
- Passionate about/experienced with open source and developer tools
Responsibilities
The Solution Engineer (SE) needs to work on challenges faced by customer and bring out cost-efficient and unique solution for the same. They are the interface between customer and the development team so that the issues can be resolved in less time. After the initial boarding, the SE is responsible for:
- Writing solution guides and best practices for MayaData products in accordance with popular Kubernetes workloads
- Updation of Helm charts for Kubera, OpenEBS and Litmus on existing as well as new marketplaces
- Testing and validating Kubera platform with hosted and self managed Kubernetes services and distribution
- Continuously learn, run Kubernetes workloads and ensure the product management receives application expectations for the top Kubernetes workloads
- Contribution in MayaData internal and external blogs
User Adoption Lead
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE’s and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations easily, and we have become open source leaders in building Kubernetes into a first-class data platform.
The role
The User Adoption Team at MayaData is looking for candidates for lead roles. MayaData is committed to producing the best Open Source solutions for managing stateful applications in Kubernetes. The UA team is responsible for outward-facing technical activity at MayaData. You will connect with other developers and SREs, drive adoption of OpenEBS, Litmus, and other Open Source Kubernetes components that MayaData develops or contributes to, and bring feedback about usage patterns from the field to MayaData Product Management.
You Will
- Reach out to users daily.
- Deliver presentations on a use case to an audience at Kubecon.
- Work through architecture and setup of cStor with prospects.
- Write blog posts about new features customers are investigating.
- Respond to inquiries on social channels.
- Lead conversations about how to run stateful applications on k8s.
- Contribute to Open Source projects that are relevant to the space.
- Channel information back to product and Engineering.
- Broker conversations with Support and Engineering teams.
- Reach developers with unique and engaging educational content.
- Meet with users, prospects, and customers.
- Conduct interviews with the media.
Requirements
3 or more of:
- Knowledge of two or more public clouds
- Knowledge of on-premise infrastructure
- Understanding of storage in a Linux environment
- Competence with 2 or more programming languages
- Expertise with Kubernetes development
- Social network with a substantial number of active, relevant followers
- Experience presenting to audiences of 300+
- Demonstrated project management expertise
- Experience serving as a media spokesperson
- Commit permissions to one or more open source projects in the space
- Portfolio of blog posts or other writing
- Expertise with large CI/CD environments
- Expertise with machine learning environments
- Experience managing partner or channel relationships
Product Manager
Ready for an opportunity to make a substantial impact with a disruptive tech company while building your Developer Advocate career in the rapidly growing Kubernetes ecosystem? Then come and PLOW with MayaData, the leading Container Attached Storage (CAS) solution for Kubernetes called OpenEBS.
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE's and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations efficiently, and we have become open source leaders in building Kubernetes into a first-class data platform.
Location: Remote (US / Europe / India Time zones)
Role description
As a MayaData Product Manager you will have the exciting opportunity to help drive the growth and shape the future of Kubera and OpenEBS through building a vibrant contributor community. In this highly technical role, you will be responsible for specific MayaData subsystems and work with our Engineering and Product teams responsible for building and delivering them to market. You will be responsible for planning and delivering product content for new releases and launches of our offerings, prioritizing and communicating product requirements to guide development, supporting the field team in advanced sales opportunities, performing competitive reviews and analysis, and working with customers and partners. You will actively contribute to the overall company strategy and work closely with Engineering, Marketing, Support, Sales, and Field teams to ensure our offerings' success. You are also expected to engage with open source communities that support our container initiatives, including Kubernetes, other Cloud Native Computing Foundation (CNCF) projects, CSI, Velero, and more. As a Product Manager, you need to have great communication, teamwork, and persuasion skills. This is a great opportunity to work on a fast-growing offering alongside some of the brightest minds in open source.
Responsibilities
- Work with the MayaData Engineering team and the overall Product Management organization to manage releases and updates of our offerings and bring new Kubera solutions to market.
- Closely works with Lead Engineers / Team Leads, serves as go to person for answering why questions. Requests grooming sessions with teams, when new work should be planned / backlog needs attention. Grooming sessions takes place regularly with intervals between 2 and 4 weeks.
- Agrees with Lead Engineer on the overall priorities, and define together the intended content for upcoming releases.
- Connect online and face-to-face with user group members to build personal relationships and deeply understand their needs, usage, journeys, and barriers to adoption
- Monitor product and project growth and health, tracking metrics and running regular group surveys
- Collect and document input from Kubera and OpenEBS users, customers, community members, and other stakeholders to understand customers' needs; develop strategy and roadmap for our offerings
- Research competitive solutions, commercial and do-it-yourself alternatives, documenting their relative strengths and weakness to develop competitive positioning and collect input for new releases
- Prioritize and document requirements, epics, and user stories for new releases of our offerings
- Guide major enhancements of our offerings by working cross-functionally with core teams across our engineering team and the upstream open source community
- Work with our Sales teams to respond to customer inquiries; deliver customer presentations and demos and support the overall sales process
- Support sales and marketing activities, including creating presentations, blogs, demos, and other technical collateral for our offerings
- Review and provide feedback on the documentation for our offerings
Requirements
- 3+ years of enterprise software industry experience working in product management, technical marketing, or a similar technical product or customer-facing role
- Experience using and contributing to open-source software
- Experience using Linux (your favorite window is a terminal)
- Experience developing for or operating Kubernetes or similar modern orchestration environments
- Excellent interpersonal and communication skills
- Positive attitude and the ability to be proactive, resourceful and flexible
- Desire to collaborate with, learn from, and inspire others
- Ability to work as a self-starter with minimal guidance
- A continual learner who thrives on figuring out new technology
- A bias for action with a capacity to iterate rapidly to produce results
- Previous experience working in an early-stage company
- Willingness to be put on display taking others with you down your learning path
- Skills in distributed systems, resource management solutions, storage technologies, software-defined networking (SDN), enterprise logging, and monitoring solutions
- Experience with Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), or similar cloud or application management solutions
- Bachelor's or graduate degree preferably in computer science, engineering, or a related discipline
The following are considered a plus:
- Practical experience with cloud platforms
- Prior experience with the agile development process
- Familiarity with Atlassian platform (Jira / Confluence) or similar project management tools
- Sound like an opportunity where you would thrive and grow? More importantly, could this be the right next step in reaching your career goals? Reach out to us and let's explore whether this role is the right fit for you.
Senior Program Manager
Ready for an opportunity to make a substantial impact with a disruptive tech company while building your Developer Advocate career in the rapidly growing Kubernetes ecosystem? Then come and PLOW with MayaData, the leading Container Attached Storage (CAS) solution for Kubernetes called OpenEBS.
At MayaData we believe that the best way to deliver storage and related services to containerized and cloud-native environments is with containerized and cloud-native architectures. Everything we do is focused on providing data agility and simplifying the daily operation of Kubernetes SRE's and DevOps teams using Kubernetes as a data layer. We enable our users to handle complex data management operations efficiently, and we have become open source leaders in building Kubernetes into a first-class data platform.
Location: Remote (US / Europe / India Time zones)
In the nutshell
We are seeking an experienced technical program manager to join the MayaData team and focus on scale and performance, TTM, and Agile Transformation. Customers are bringing more intensive, mission-critical workloads to the platform every day, and we must continue pushing the boundaries of Kubernetes to meet their needs. You will be at the forefront of the industry helping customers run their workloads at scale and optimize their performance. You will focus on the next generation of highly performant, and resilient block storage software, in an open source environment and have the chance to participate and share with the upstream Kubernetes community. We're looking to augment a fast moving team with a diverse set of skills among its members. Global Program Management Skills a strong plus.
Responsibilities
- Listen and learn from customers and partners.
- Define and Drive to completion full product program management content and schedules.
- Provide guidance, define and execute real time communications program management: Digital operations via Jira burndowns, and other visible tracking tools.
- Define and drive Agile Transformation, functional delivery at scale.
- Define and track success metrics for the product and the business.
- Define best in class Atlassian based Agile practices and execution.
- Prioritize the engineering roadmap in accordance with engineering resource allocation and drive against the commitments.
- Partner closely with product to assure customer satisfaction and TTM.
- Participate with a global, world class startup in a hyper-growth environment.
Requirements
- 3-5+ years of experience as a Technical Program Manager; BS in computer science, MBA or engineering management equivalent preferred.
- Experience in SaaS development environments is preferred.
- Demonstrated change agent with capabilities to identify and deliver on process changes that would enable faster time to market while driving organization consistency and efficiency.
- Proven expertise in managing projects throughout the entire SDLC, including investigation, design, execution, testing, maintenance, documentation and delivering products to market on schedule, and addressing customer feedback in development.
- Solid project and technical judgment; ability to influence a growing organization.
- Strong team and customer focus.
- Experience in a variety of development methods including Scrum, Kanban, and Waterfall. Run daily stand-ups and monitor the velocity of the team.
- Optimize team processes to improve quality, engineering productivity, and responsiveness to feedback and changing priorities.
- Overcome obstacles by resolving issues, regardless of team boundaries, and identify and resolve teamwork issues.
- Familiarity with codeline management and associated Linux-based tools.
- Solid knowledge of end-to-end quality best practices.
- Demonstrated strong analytical and problem solving skills.
- Outstanding verbal and written communication skills with the ability to interact with technical and non-technical, cross-functional groups.
Site Reliability Engineer
Site Reliability Engineers (SREs) are responsible for keeping all user-facing services and other MayaData production systems running smoothly. SREs are a blend of pragmatic operators and software craftspeople that apply sound engineering principles, operational discipline, and mature automation to our environments and the MayaData codebase.
Our vision is to enable a new era of workload based data management by turning Kubernetes itself into a data plane. This use of Kubernetes as the data plane boosts the productivity and control of software development groups while decreasing cloud and vendor lock-in.
We focus on the jobs that our users need to get done in order to trust Kubernetes as their data layer. Specifically, we focus upon:
- Ease of deployment and operations of stateful workloads on Kubernetes
- Simplicity of data protection including replicas, back-ups and data migration
- Automatic and seamless protection from lock-in, via background rebalancing or on demand data migration
MayaData has several user facing sites that include many websites, documentation portals, build/CI platforms and a biggest OpenEBS storage powered SaaS Platform - called OpenEBS Director. In fact, OpenEBS Director is one of the largest SaaS sites providing Storage observability to serveral Kubernetes clusters across the world. OpenEBS Director is also delivered as a software product, to be installed in user's premises.
All of our workloads are powered with Kubernetes and OpenEBS Storage. The experience of our team feeds back into other engineering groups within the company, as well as to MayaData customers running self-managed installations of OpenEBS and OpenEBS Director.
As an SRE you will:
- Be on a PagerDuty/Slack rotation to respond to MayaData availability incidents and provide support for service engineers with customer incidents.
- Use your on-call shift to prevent incidents from ever happening.
- Run our infrastructure with Ansilbe, Terraform, GitOps and Kubernetes.
- Make monitoring and alerting alert on symptoms and not on outages.
- Document every action so your findings turn into repeatable actions–and then into automation.
- Use the MayaData products to run Director as a first resort and improve the product as much as possible
- Improve the deployment process to make it as boring as possible.
- Design, build and maintain core infrastructure pieces that allow MayaData scaling to support hundred of thousands of concurrent users.
- Debug production issues across services and levels of the stack.
- Plan the growth of MayaData's infrastructure.
You may be a fit for this role if you:
- Think about systems - edge cases, failure modes, behaviors, specific implementations.
- Know your way around Kubernetes, Grafana, Prometheus, MySQL, Cassandra, Linux and the Unix Shell.
- Know what is the use of config management systems like GitHub, GitLab, Ansible
- Have strong programming skills - Python and/or Go
- Have an urge to collaborate and communicate asynchronously.
- Have an urge to document all the things so you don't need to learn the same thing twice.
- Have an enthusiastic, go-for-it attitude. When you see something broken, you can't help but fix it.
- Have an urge for delivering quickly and iterating fast.
- Share our values, and work in accordance with those values.
- Have experience with GKE, Nginx, HAProxy, Docker, Kubernetes, Terraform, or similar technologies
- Ability to use MayaData products like OpenEBS, Litmus, Director
- You love sharing your learnings with other folks within and outside the company through Meetups, Conference talks and so forth.
Projects you could work on:
- Coding infrastructure automation with Terraform, Ansible, Python and other SaaS products
- Improving our Prometheus Monitoring or building new Metrics
- Helping release managers deploy and fix new versions of Director and OpenEBS.
- Helping customers manage their solutions/installations of OpenEBS and OpenEBS Director.
- Plan, prepare for, and execute the migration of Stateful Workloads running on OpenEBS and Director on Kubernetes - handling the upgrades and auto-scaling of Kubernetes Clusters, Geo-distribution of the applications.
- Plan and automate setting up of Stateful Workloads on Kubernetes on different platforms from virtual machines to different cloud providers like - GKE, AKS, AWS, OpenShift.
- Develop a relationship with a product group, define their SLAs, share Mayadata production sites data on those SLAs and improve their reliability
Leveling of Site Reliability Engineering
Technical:
- Use automation to efficiently manage our fleet of servers
- Implement "Infrastructure as Code" using Terraform, Flux, Helm and GitLab/Jenkins/Travis CI/CD, for automation
- Kubernetes and containerizing our system
- Product knowledge of OpenEBS, Director, Litmus and the eco-system products deployed on Director.
- Monitoring and Metrics in Prometheus, Grafana and integrations with Slack/PagerDuty
- Logging infrastructure
- Running Stateful Workloads at scale using OpenEBS, along with Infrastructure and Storage Management
- Disaster Recovery and High Availability strategy
- Contributing to code in MayaData
Execution:
- Team organization and planning
- Issue, Epic, OKR leadership and completion
Collaboration and Communication:
- Creating blog posts
- Completing Root Cause Analysis (RCA) investigations
- Contributions to handbook, runbooks, general documentation
- Leading and contributing to designs for issues, epics, okrs
- Improving team practices in handoffs of work and incidents
Influence and Maturity
- Involvement in the hiring process - reviewing questionnaires, involved in interviews, qualifying candidates
- Knowledge sharing, mentoring
- Accountability, Self awareness, handling conflict in the team and receiving feedback
- Maintaining good relationships with other engineering teams in MayaData that help improve the product
Levels for Site Reliability Engineer
Junior Site Reliability Engineer
Technical:
- Updates MayaData Director and OpenEBS default values so there is no need for configuration by customers.
- General knowledge of the 2 of the areas of technical expertise
Execution:
- Provides emergency response either by being on-call or by reacting to symptoms according to monitoring and escalation when needed
- Delivers production solutions that scale, identifies automation points, and proposes ideas on how to improve efficiency.
- Improves monitoring and alerting fighting alert spam.
Collaboration and Communication:
- Improves documentation all around, either in application documentation, or in runbooks, explaining the why, not stopping with the what.
Influence and Maturity
- Shares the learnings publicly, either by creating issues that provide context for anyone to understand it or by writing blog posts.
Site Reliability Engineer
Technical:
- General knowledge of the 4 of the areas of technical expertise with deep knowledge in 1 area
Execution:
- Provides emergency response either by being on-call or by reacting to symptoms according to monitoring and escalation when needed
- Proposes ideas and solutions within the infrastructure team to reduce the workload by automation.
- Plan, design and execute solutions within the infrastructure team to reach specific goals agreed within the team.
- Plan and execute configuration change operations both at the application and infrastructure level.
- Actively looks for opportunities to improve the availability and performance of the system by applying the learning from monitoring and observation
Collaboration and Communication:
- Improves documentation all around, either in application documentation, or in runbooks, explaining the why, not stopping with the what.
Influence and Maturity:
- Shares the learnings publicly, either by creating issues that provide context for anyone to understand it or by writing blog posts.
- Contributes to the hiring process in review questionnaires or being part of the interview team to qualify SRE candidates
Senior Site Reliability Engineer
Technical:
- Deep knowledge in 2 areas of expertise and general knowledge of all areas of expertise. Capable of mentoring Junior in all areas and other SRE in their area of deep knowledge.
- Contributes small improvements to the MayaData codebase to resolve issues
Execution:
- Identifies significant projects that result in substantial cost savings or revenue
- Identifies changes for the product architecture from the reliability, performance and availability perspective with a data driven approach.
- Proactively work on the efficiency and capacity planning to set clear requirements and reduce the system resources usage to make OpenEBS and Director cheaper to run for all our customers.
- Identify parts of the system that do not scale, provides immediate palliative measures and drives long term resolution of these incidents.
- Identify Service Level Indicators (SLIs) that will align the team to meet the availability and latency objectives.
Collaboration and Communication:
- Know a domain really well and radiate that knowledge
- Perform and run blameless RCAs on incidents and outages aggressively looking for answers that will prevent the incident from ever happening again.
Influence and Maturity:
- Lead Production SREs and Junior Production SREs by setting the example.
- Show ownership of a major part of the infrastructure.
- Trusted to de-escalate conflicts inside the team
Staff Site Reliability Engineer
Technical:
- Able to create innovative solutions that push MayaData’s technical abilities ahead of the curve
- Deep knowledge of Director and OpenEBS and 4 areas of expertise. Knowledge of each area of expertise enough to mentor and guide other team members in those areas.
- Contributes to MayaData codebases to resolve issues and add new functionality
Execution:
- Strives for automation either by coding it or by leading and influencing developers to build systems that are easy to run in production.
- Measure the risk of introduced features to plan ahead and improve the infrastructure.
- Proposes and drives architectural changes that affect the whole company to solve scaling and performance problems
- Leads significant project work for OKR level goals for the team
Communication and Collaboration:
- Works with engineers across the whole company influencing design to create features that will work well with SaaS and self hosted platforms
- Runs RCAs and epic level planning meetings to get meaningful work scheduled into the plan
Influence and Maturity:
- Writes in-depth documentation that shares knowledge and radiates OpenEBS and Director’s technical strengths
- Has a high level of self awareness
- Trusted to de-escalate conflicts inside and outside the team
- Routinely has an impact on the broader Engineering organization
- Helps to develop other team members in to senior levels and leaders in the team
Engineering Fellow, Infrastructure
The Infrastructure Fellow embodies all the requirements of less senior roles on this page. In addition, the role is closely associated with Engineering Fellow role in our Development Department.
- Drive the technical strategy of of our MayaData Director and other Infrastructure
- Heavily influence the technical strategy of our open-source application maintained by our Development Department
- Make skill-gap recommendations for future hiring in Infrastructure and other departments
- Author technical vision artifacts with >1 year time horizon
- Assist teams throughout Engineering to interpret this vision into actionable backlogs
- Help Engineering avoid the architecture "ivory tower"
- Spend time with customers to learn their needs
- Considered as an authority in all topics SRE by MayaData and its community.
Performance Indicators
Site Reliability Engineers have the following job-family performance indicators:
- Director and other sites Availability
- Director and other sites Performance
- Apdex and Error SLO per Service
- Mean Time to Detection
- Mean Time to Resolution
- Mean Time Between Failure
- Mean Time to Production
- Disaster Recovery Time to Recovery
Hiring Process
All interviews are conducted using Zoom video conferencing software or in person. To learn more about someone conducting your interview, find their job title on our team page.
Please keep in mind that you can be declined at any stage of the process. You should consider each of the following bullets as though the words, "If selected" precedes them.
- You will receive a technical questionnaire to complete.
- You will be invited to schedule a 30 minute screening call.
- You will discuss your technical skills for 60 minutes with a member of the Reliability Engineering team.
- You will have 2-3, 45 minute team interviews with at least one Site Reliability Engineer.
- You will talk for 60 minutes with a Reliability Engineering hiring manager.
It's possible you may have additional 60 minute interviews with either the Director of Infrastructure Engineering, the Director of Engineering, or both.
If approved, you will subsequently be made an offer.
Additional details about our process can be found on our hiring page.
We are an equal opportunity employer and value diversity and inclusion at our company. We do not discriminate on the basis of race, religion, color, national origin, gender, sexual orientation, age, marital status, veteran status, or disability status.
Hiring
-
This is not a listing of open positions, but rather provides details on what you can expect during hiring process for a given role or expected to do once you have onboarded. For a list of open positions, refer to our careers page: https://mayadata.io/careers
-
Each hiring process for a job role will begin with the job responsibility spec(JRS) and 6-12 months plan. There will be multiple levels defined under each job role depending on the individual's experience in performing the duties outlined in the JRS. New JRS can be added by raising a pull request.
-
We will always be open to hiring the right individuals that complement the skills of the team from anywhere in the world, by compensating as per the market standards.
-
We will project and plan the budget as much as possible. However, the release milestones will not wait for resources to join and ramp-up.
-
Being part of a winning startup, people at MayaData are expected to be really good at one thing that they specialize in and stay accountable for as outlined in our PLOW values. The accountability is self-driven through OKRs and 1-1s with respective managers.
-
Each MayaData employee will specialize and be accountable for a product or component, and can also be an expert in other product/component or technology areas. An individual’s role will be defined as follows:
[Level] [Job Role Name] as defined in the JRS Specialist: [Product/Component Name] Expert: [Product/Component Name, Technology Area]Example:
Senior SRE Specialist: OpenEBS Director Expert: Terraform, GKE, GitLab -
When individual team members may be required to play dual or multiple roles to help make progress on the milestones while the new hires or team members join, the impact is analyzed and documented in the OKRs and 1-1s. We will be sensitive to the current skills and career ambitions of the individuals.
Objectives and Key Results
“Objectives and key results are the yin and yang of goal setting.” from John Doerr’s Measure What Matters
At MayaData we believe in PLOW culture where everyone is committed and accountable to working as a team to deliver company objectives. OKRs provide the best mechanism to gain visibility into everyone’s objectives. OKRs expose redundant efforts and save time and money.
OKRs lay out our plan to execute our strategy and help make sure we achieve them with clearly defined goals throughout the organization.
OKRs help in providing clarity and alignment in terms of what needs to be accomplished by an individual.
OKRs are also a great tool for individuals to stay focused on what they have agreed to accomplish for the company.
OKRs provide both top-down and bottom-up alignment.
OKRs allows managers and individuals to step away from the need for Micromanagement - which is more a sign of mismanagement or an ineffective team composition.
OKRs is a key enabler for our culture that helps each individual to realize their personal dreams and aspirations, while staying committed to helping MayaData customers succeed in their jobs.
OKRs
OKRs stand for Objective- Key Results and are our quarterly objectives.
OKRs are of the following format:
OBJECTIVE as a sentence.
KEY RESULTS:
* Key result that is measurable
* Key result that is measurable
* Key result that is measurable
You can use the phrase “I will achieve a certain OBJECTIVE as measured by the following KEY RESULTS…” to know if your OKR makes sense.
OKRs must be defined for each Quarter with a maximum of four objectives. An individual’s OKRs must a mix of:
- 3 Primary role objectives and
- 1 Personal career aspiration objective.
Each objective has between 1 and 4 key results; if you have less, you list less.
The Startup OKR template provides a good explanation on how to go about writing the OKRs.
Objectives:
The goal of setting> an Objective is to write out what you hope to accomplish such that at a later time you can easily tell if you have reached, or have a clear path to reaching that objective.
Choosing the right objectives is one of the hardest things to do and requires a great deal of thinking and courage to do well.
Key Results:
Assuming your Objectives are well thought through, Key Results are the secret sauce to using OKRs. Key Results are numerically-based expressions of success or progress towards an Objective.
The important element here is measuring success. It’s not good enough to make broad statements about improvement (that are subjectively evaluated). We need to know how well you are succeeding. Qualitative goals tend to under-represent our capabilities because the solution tends to be the lowest common denominator.
Example:
Consider an objective called
launch new training for the sales team. This can be accomplished by an individual by putting out a training material out there or by testing the material with a single sales member. However a good key result would be one that can be easily measured and is a stretch - liketrain 50 sales team members. It is possible that the individual can end-up training only 10, but it is better than just publishing or training a single person. The performance of the individual jumped 10-ex with properly articulating the key result.OBJECTIVE: launch new training for the sales team KEY RESULTS: * publish new training material on company portal * train 50 sales team members
OKRs are meant to be ambitious and hard to achieve. Usually, it isn’t expected that anyone hits 100% of an OKR. Expected performance is generally:
- If you hit 70% of the Key Result, it's considered a positive.
- If you hit 110% of the key result, that's a likely sign that the individual and manager who oversaw the OKR didn't manage it well and set the goal too low.
- If you get 50% or less, it's possible that
- Priorities changed
- The employee did a poor job working on the objective
- The Key Result was set poorly (too high).
It takes 2 - 4 quarters to get skilled at setting OKRs; your first few times setting goals you will likely be all over the place in terms of OKR completion at the end of a quarter. That’s normal. As you get better, you should be able to scope out the quarter’s work and performance with more confidence.
OKR Setting Process
OKR setting is highly collaborative process and takes time and discipline to get it right. OKRs are widely shared and meant to be understood by teams and individuals. Each individual must have their OKRs reviewed by their Technical Lead, People Manager, Peers and/or their mentor.
OKR cycle
-
By the 1st of the quarter, CEO (Company) and Executives (department) OKRs are published. This process typically starts off towards the last month of the previous quarter where CEO and executives meet to plan for the next quarter and align their OKRs.
-
By the 15th of the first month in a quarter the OKRs are reviewed and published along with the all-hands. This process involves:
- Technical or Team Leads publishing their OKRs that are aligned with the CEO/Executive OKRs
- Individuals share their OKRs in alignment with their Team / Technical Lead OKRs and it is also possible that some of the objectives may be directly aligned towards CEO/Executives. As we taken on cross functional or multiple roles as required by the Startup culture.
- Individual and Team OKRs are reviewed and updated. The feedback from the Individual OKRs conducted as a team will translate into updating the Team/Technical Lead, Individual or eventually the Executive OKRs.
- For the personal objectives, the Individual should seek help from People Manager or mentors for review.
-
By the 15th of the second month a mid-review score is updated by the individuals
-
By the 30th of the third month the final reviews are completed and work on the next Quarters reviews are started.
Technical Leads
Technical Leads are responsible for a product or a complete feature. Technical Leads have to work with many other individual contributors to accomplish a larger goal.
When the goals set through OKRs are not being accomplished due to any number of reasons including under performing individuals to complex features, the TL can redistribute the tasks to accomplish the goal.
Technical leads are responsible for accomplishing the product/company goal and not responsible for evenly distributing tasks to employees or worrying about the career growth. Individuals have to take ownership for their goals and career growth and seek help from mentors or people managers.
Types of Meetings with TL
The outcome of each of these meetings is captured in tools or documents that is available for everyone in the company to consume.
- Daily and Weekly Standup
- 1:1 or Team OKR Review Meetings
- 1:1 or Team Knowledge Sharing sessions
- Release Planning
- Design Reviews
People Managers
People Managers are responsible for helping individuals bring and deliver their best to MayaData. People Manager abide by PLOW / culture handbook.
Individuals need to work out with the People managers for their career growth objectives and have them self aligned with the roles and responsibilities outlined in the culture handbook.
People Managers are required to update the PLOW/culture handbook when responding to the queries that are common to all the individuals. For instance, PLOW / culture handbook should be referred when answering anything related and not limited to:
- Questions on Leave Management via Tools and Policy
- Event Sponsorships via Developer Advocacy Handbook
- Career Growth via Roles and Responsibilities
People Managers can be reached out to queries or concerns related to Salary and Benefits, which can then be answered via updates to the PLOW policy or through contacting the HR.
Types of Meetings with People Managers
The outcome of each of these meetings is captured in a document and is confidential between the individual and the people manager. Some outcomes discussed in the meeting that are useful for others in the organization like updating the PLOW can be shared to every-one.
- 1:1 Performance Review Meetings scheduled at least monthly and increasing the frequency depending on the individual’s needs.
- On-demand meetings with Manager or the People Ops contact to discuss about burn-out situations, personal emergencies, vacation planning, PLOW values violation and so forth.
Mentors
Mentors are experts or have experience in a given area/topic and others in the organization can seek the help from Mentors to learn or gain experience in that area/topic.
Anyone can be mentors. Mentors can be senior or junior in experience than the mentee.
Mentor:mentee sessions are completely optional and if taken, must be taken seriously. The PLOW values of committing and respecting also apply to Mentor:mentee meetings. Schedule and prepare for the meetings with a clear agenda. Once the goals are met, discuss and either reduce the frequency or end the sessions. Make room for other learning experiences.
Mentor discussions should not be confused with better performance reviews or salary discussions, that must be had with People Managers.
Mentor sessions are inherently meant to be only individual centric, positive and objective to foster learning. Avoid using these sessions to provide negative feedback on others in the organization. You can also seek help or learn on how to handle hard situations or how to better communicate - without turning the sessions into venting channels. Use people ops communication channels to report any violation of PLOW values.
Mentors are required to abide by the PLOW values and help improve them.
Types of Meetings with Mentors
The outcome of each of these meetings is captured in a document that is shared between the mentor and mentee and some information that is useful in a positive way can be shared to every-one.
- 1:1 Mentor-mentee meetings with frequency as decided by the mentor and mentee.
References
Paid Time Off
This page is written with a focus on vacation/leave policies taken towards Paid Time Off.
MayaData allows for 15 days of Personal Time Off or Vacation Days or Paid Time Off days that are in addition to:
- National Holidays governed by your location
- Leaves taken for medical needs, whether physical or mental
- Leaves taken towards major life changing events like becoming a parent, losing a family member
- Leaves taken to fulfill your duties as a citizen to your nation like Voting Leave or Jury Duty leave and so forth.
MayaData recognizes that it is very important to take time off to recharge batteries and refresh the mind so you can come back to your work and commitments with renewed energy and be prepared to do your best work ever! MayaData also encourages you to use your leave for medical needs, jury duty, bereavement leave, or to vote. You are not expected to work during this time off, but we recommend following the guidance under Communicating Your Time Off when these situations arise.
Time away from work can be extremely helpful for maintaining a good work/life balance. MayaData encourages managers and leadership to set the example by taking time off when needed, and ensuring their reports do the same.
PTO do not have to be trips to exotic places, but instead could be taking some time for oneself at home. A great example for a personal time off is to take care of long outstanding chores at home, or to provide medical care to a family member or a friend.
Working hours are flexible. You don't need to worry about taking time off to go to the gym, take a nap, go grocery shopping, do household chores, help someone, take care of a loved one, etc. If you have urgent tasks, but something comes up or takes longer than expected, just ensure the rest of the team knows and someone can pick up the tasks (assuming you're able to communicate). When your personal work keeps your away from work and are unable to put in the required hours to complete your tasks per day, we trust that you will use your time off and communicate it to your manager and team.
Guide to use Paid Time Off
As we all work remotely it can sometimes be difficult to know when and how to plan time off. Here is some advice and guidance on how this can be done in an easy and collaborative way.
- We have a "no ask, must tell" time off policy. This means that:
- You do not need to ask permission to take time off unless you want to have more than 4 calendar days off in a release cycle that runs from 15th to 15th of every month. The 4 day limit is to ensure that business continuity is maintained.
- What we care about are your results, not how long you work. While you don't need to ask approval for time off, it shouldn’t be at the expense of business getting done. Please coordinate with your team before taking time off, especially during popular or official holidays, so that we can ensure business continuity. We want to ensure we have adequate coverage and avoid situations where all/most of the team is taking time off at the same time.
- When taking time off make sure your manager is aware of your absence. Informing your manager can be done by sending a shout out in the #announcements slack and also including your local HR contact. Giving your manager and team members a heads up early helps them prioritize work and meet business goals and deadlines.
- If you're gone for 48 hours without prior notification, this could be deemed as a case of Job Abandonment.
- It can be helpful to take longer breaks to re-energize. If this is helpful to you, we strongly recommend taking at least two consecutive weeks of time off per year.
- We don't frown on people taking time off, but rather encourage people to take care of themselves and others by having some time away. If you notice that your co-worker is working long hours over a sustained period, you may want to let them know about the time off policy.
- Not taking vacation is viewed as a weakness and people shouldn't boast about it. It is viewed as a lack of humility about your role, not fostering collaboration in training others in your job, and not being able to document and explain your work. You are doing the company a disservice by being a single point of failure. The company must be able to go for long periods without you. We don't want to lose you permanently by you burning yourself out by not taking regular vacations.
- You are invited to the company call and your team calls if you are available, but it isn't mandatory and you shouldn't attend if it is during your time off. We encourage you to read the call agenda on your return to catch up on the announcements made while you were on your time off.
- Please also remember to turn on your out of office message and include the contact details of a co-worker in case anything urgent or critical comes into your inbox while you're away. If you have to respond to an incident while on-call outside of your regular working hours, you should feel free to take off some time the following day to recover and be well-rested. If you feel pressured to not take time off to rest, refer to this part of the handbook and explain that you had to handle an incident.
- When returning from paid time off, it can be helpful to schedule a coffee chat or two on the day of your return to get caught up, share stories from your time off, and simply reconnect with your team members. It also provides a nice break from to-dos and unread emails. This type of conversation may occur organically in a colocated office but needs to be managed with intent in an all-remote company.
Communicating Your Time Off
Communicate broadly when you will be away so other people can manage time efficiently, projects don't slip through the cracks, and so that you don't get bothered while away.
- If you plan to be out of the office for more than 48 hours, update your Slack status with your out of office dates by clicking on your profile picture and selecting "Edit Status." For Example: 'OOO Back on 2020-02-20.' Don't forget to change it back upon your return, and be aware that this information is publicly accessible.
- Add an out of office automated response including the dates you plan to be away in your automated response.
- Decline any meetings you will not be present for so the organizer can make appropriate arrangements.
- If your team or work group has a specific scheduling calendar, ensure to update it with your out of office plans. Bring it up in your team standups
Communicating Time Off for an Emergency Situations
Emergencies, by definition are unexpected. They can range from natural disasters, terrorist events, accidents, family deaths, hospitalization and any other unexpected situation. During these times we ask team members to use their best judgement as well as listen to and adhere to public safety officials when possible. If an unexpected emergency occurs please contact your manager via slack or email or phone as soon as possible if you will be unavailable or unable to work. This will allow your manager to confirm your safety and reassign any critical work during your absence. If you do not have an emergency contact provided to your HR please go ahead and complete that section. We will only contact that person if we are unable to reach you via slack, email or phone.
Recognizing Burnout
It is important for us to take a step back to recognize and acknowledge the feeling of being "burned out". We are not as effective or efficient when we work long hours, miss meals or forego nurturing our personal lives for sustained periods of time. If you feel that you or someone on your team may be experiencing burnout, be sure to address it right away.
To get ahead of a problem, be sure to communicate with your manager if any of the following statements ever apply to you:
- "I am losing interest in social interaction." - This is especially dangerous in an all-remote setting.
- "I've lost the motivation to work." - Everyone has days when they don't want to work but if you hear yourself saying this often, you're on the road to burnout.
- "I often feel tired." - Indicative of being overworked for prolonged periods of time.
- "I get agitated easily."
- "I've been hostile to my coworkers." - You see yourself "snap" at people for no apparent reason.
- "I've been having headaches often." - A headache can manifest itself for multiple reasons but if you catch yourself only having headaches on work days, it is time to evaluate your situation.
If someone is showing signs of burnout, they should take time off to focus on things that are relaxing and improve their overall health and welfare.
Other tips to avoid burnout include:
- Assess and pursue your interests, skills and passions.
- Take breaks during the day to eat healthy food and stretch your legs. The Timeout app can help with that.
- Make time each day to increase blood and oxygen circulation which improves brain activity and functionality.
- Get plenty of restful sleep.
- Meditate to take your mind away from work. Headspace and Calm are good tools for creating meditation habits.
- Don't start work as soon as you wake up. Take your time doing your morning routine.
- Set yourself as away when you are not working. Snooze your Slack notifications. It is fine to be not reachable during your off time.
- Don't let burnout creep up on you. Working remotely can allow us to create bad habits, such as working straight through lunch to get something finished. Once in a while this feels good, perhaps to check that nagging task or big project off the list, but don't let this become a bad habit. Before long, you'll begin to feel the effects on your body and see it in your work.
Keep in mind that you are not alone! Chances are that you have a colleague who already experienced burnout or has been on the road to burnout. Schedule coffee calls with your team members or with anyone you'd like to talk to. Talk to your manager. If none of that is an option for you, schedule a call with your HR Manager.
Take care not to burn yourself out
Management’s Role in Paid Time Off
Managers have a duty of care towards their direct reports in managing their wellbeing and ensuring that time off is being taken. Sometimes, when working remotely from home, a good work-life balance can be difficult to find. It is also easy to forget that your team is working across multiple time zones, so some may feel obligated to work longer to ensure there is overlap. It is important that you check-in with your reports through one-to-ones, and if you think someone needs some time off let them know they can do this.
If you discover that multiple people in your team want to be off at the same time, see what the priorities are, review the impact to the business, and use your best judgement. Discuss this with your team so you can manage the time off together. It is also a good idea to remind your team to give everyone an early heads-up, if possible, about upcoming vacation plans.
As a manager, it is your task to evaluate your team's state of mind. Address possible burnout by discussing options with your team member to manage contributing stressors and evaluate the workload. Some things to help with this:
- Try to follow each of your team members' work habits. If they start being less efficient, or working more hours, they might be on the road to burnout.
- Try to keep track of when they had their last paid day off. If they hadn't had a personal day in a long time, look closer at their behaviour.
- Make sure you let your team members know they can talk to you about their challenges.
- When you recognize symptoms of burnout in others, help them to get out the "Burnout trap". Don't just tell people to take a break, but help them arrange things so they can take a break. Ask why they feel they can't take a break (there are almost certainly real, concrete reasons) and then ask permission to get busy putting things in place that will overcome those barriers. People might be trapped by their own fatigue, being too worn out to find the creative solutions needed to take a break.
Saying Goodbye
At MayaData we are on a multi-year journey during which our products, our customers, our market, our community - and yes the macroeconomic and public health environment - are all undergoing changes. It would be unreasonable to expect that the company would not also undergo changes; it would also be unfair to assume stasis, unfair to ourselves and our customers and users and all other stakeholders if we didn’t reexamine ourselves critically in order to constantly improve MayaData.
At MayaData, having ourselves committed to People First, it is very challenging and even feels unpleasant to say Goodbyes. However, People First with our other values in PLOW with the imperative of growing and evolving the company is to recognize that the team is of greater importance than any individual.
At MayaData, our policy is to be the preferred place to work in our markets for individuals that want to cast themselves into the tumult and opportunity of a start-up in order to achieve our mission. We compete for the best and brightest not via cash and other compensation alone - but via mission, culture, opportunity, and challenge.
Goodbyes are inevitable.
-
At a certain point, individuals will no longer fit with the team. Perhaps they’ll decide that MayaData no longer helps them grow in the way they feel is best. Or perhaps they’ll be recruited to by an enormous organization - and they’ll decide that start-up life is no longer compatible with the kind of life they want for themselves. Maybe they’ve developed themselves all they want or need and in some cases personal circumstances cause them to value stability over growth and opportunity.
-
Or, perhaps MayaData will decide that the individual is no longer the best fit for MayaData. No company or organization has unlimited funds or resources. Every organization must decide where to spend scarce resources in order to achieve challenging goals. Unfortunately, this can mean deciding that some of the team members that helped us in the past are no longer a fit for us in the future.
In either case, our policy is to bid the individual a swift adieu - to say thank you and Godspeed.
A lingering end to the relationship of an individual with a team puts at risk the cohesion of the team and closes off opportunities for growth for those that remain.
Specifically, our policy is to pay a reasonable transition to those that we ask to leave the company and not expect them to continue to work with us during that time; while some transition time may be required and helpful, the shock of change is part of what catalyzes a team to take a new approach to new and old problems. Similarly, while we appreciate that it is customary to give notice when resigning from an organization, this does not mean that we want employees that have left the team to continue to take up space, opportunity, resources, and time once they have decided to move on.
In short - we seek to enable a transition to occur within one day or at most a week.
While respecting and making the transition very swift for the outgoing team member, the rest of the team pulls themselves quickly together to look at reality directly - the objectives are the same or even more daunting, and now one of your own is no longer with us. What are we going to do about it? What are you going to do to step up and help the work happen better, faster, with a tighter alignment to our mission and immediate goals?
Here are some guidelines for managing the Goodbyes.
- Openness is one of our values. In the case of Goodbyes, we opt to share the feedback only with peers and reports of the person since we balance Openness with our value of People first and negative is 1-1. Goodbyes can be painful, may be a learning opportunity for some, but should not be a point of gossip for anyone. If the departing team member gives their manager permission to share that information then the manager will share while making the departure announcement on the team call. We want all team-members to be engaged, happy and fulfilled in their work and if the requirements of the job or the role itself are not fulfilling we wish our team members the best of luck in their next endeavor.
- When dealing with involuntary Goodbyes certain information can be shared. Some team members do not thrive or enjoy the work that they were hired to do. For example after starting at MayaData a team member quickly learns they have no desire or interest to work on Infrastructure products. This doesn't make them a bad person, it just means they don't have the interest for the role and based on that the decision was made to exit the company. Again, we want all team members to enjoy and thrive in their work and that may or may not be at MayaData.
- If someone is let go involuntarily, this generally cannot be shared since it affects the individual's privacy and job performance is intentionally kept between an individual and their manager. If you are not close to an employee's offboarding, it may seem unnecessarily swift. According to our values negative feedback is 1-1 between you and your manager and we are limited in what we can share about private employee issues. Please discuss any concerns you have about another employee's offboarding with your manager.
- In both types of Goodbyes, we follow the guidelines outlined by the local laws. For example in the US, a Separation and Release of Claims Agreement needs to be signed between the ex-team member and their people manager prior to releasing the separation pay. People manager will consult the HR and legal teams prior to executing the Goodbyes.
Job Abandonment
When a team member is absent from work for two consecutive workdays, there is no entry on the availability calendar for time off, and fails to contact his or her supervisor, they can be terminated for job abandonment unless otherwise required by law.
If a manager is unable to reach an employee via email or slack within a 24 hour period they should contact their HR Business Partner. The HR Business partner will access the employee's information to obtain additional contact methods and numbers. The manager and HR Business Partner will create an action plan to make all attempts to contact the employee.
Paid Time Off
Paid Time Off (PTO) policy is applicable to all direct employees of the company. PTO is not applicable for Contractors, Trainees or Interns at the organization.
Employees would be eligible for a fixed number of PTO days per calendar year (January to December). The exact number of PTO days can vary depending on the local laws of the location of the Employee. For instance, Employees from India are entitled to 15 PTO days in every calendar year (January to December), and are credited with 1.25 PTO days at the completion of every month from the date of joining.
Employee can avail PTO days as many times as required during the calendar year (January to December) or from the date of joining provided:
- Employee has PTO days available.
- Employee has prior approval from the reporting manager, when availing more than 4 days of consecutive PTO days. A manager has the discretion to not approve a leave based on performance issues or critical deadlines.
- Employee has informed the reporting manager about the intent to avail PTO days, prior to or on the day of availing the PTO Day.
- Employee is expected to keep their team and reporting manager informed about their PTO plan in advance to ensure that someone else can manage important tasks while they are away.
- Employee is expected to report their availed PTO days using the tools setup by the HR/Payroll department. Any violation in reporting can result in a corrective action. Here are some ways to communicate the PTO days:
- Send out an note in the #announcement channel - tagging your reporting manager and your local HR manager.
- Set the Status of your Slack with the duration of your PTO days.
When availing unplanned PTO, the employee is required to communicate their absence of work within 24 hours to their manager.
If an Employee has not sent notification of absence / or has not reported to work for 72 hours, it will be considered as Job abandonment and corrective action will be taken against the Employee, possibly leading to termination of services. Check the Job Abondonment Policy.
If an employee needs to be away from work for longer than the available PTO days, then Loss of Pay Leave policy will be applied for the exceeded days. The PTO days cannot be set off against or combined with any other kind of leave - like sick days off.
If an employee needs to take paid leave during popular holidays, they are required to apply for leave at least 2 months prior to the leave dates. They are requested to keep their manager and team members informed before availing the approved leave. This is to ensure that our business operations are not affected during the popular holidays when there is a possibility of more team members taking off.
Unused PTO days in the current calendar year will be carried forward to next year. A maximum of 45 unused PTO days can be accumulated over the years of service at MayaData. The unused PTO (up to a maximum of 45) days will be encashed only at the time of resignation or retirement.
Unused PTO days cannot be offset against the notice period required to be given as part of the terms of employment while the employee is offboarding their services from the company.